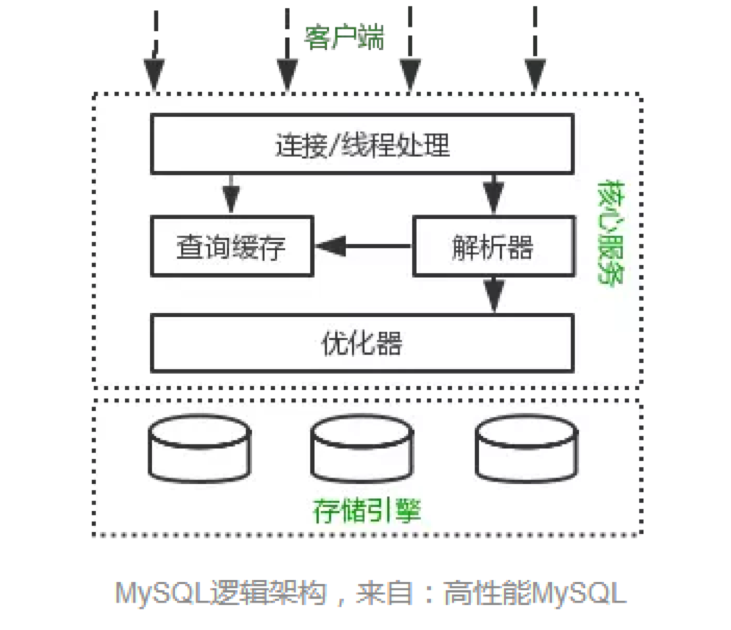
mysql的逻辑架构大概分为三层:
第一层: 服务层(为客户端服务)
为请求做连接处理,授权认证,安全等。
第二层:核心服务
比如查询解析,优化,缓存,内置函数。存储过程,触发器,视图等。对于第二层来说,所以跨存储引擎的功能都在这一层实现。
第三层:存储引擎
负责mysql中数据的存储和提取。服务器通过api与存储引擎通信,这些接口屏蔽了存储引擎之间的差异。也就是说,接口的存在,导致不同存储引擎的差异不会影响到上层查询过程。
架构分层之后,可以更好的理解一些问题,比如我们很关心的并发问题:mysql层面的并发控制,实际上是分为两种:
- 服务层的并发
- 存储引擎层的并发的
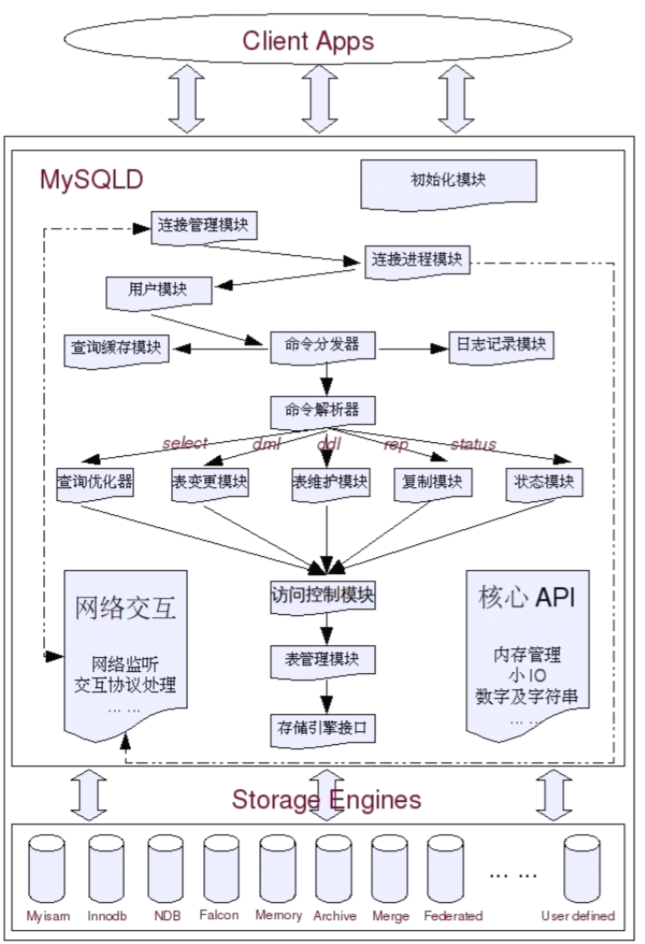
我们来看看各模块之间是如何配合的:(为了看得清楚,把模块都用【】框了出来)
- 【初始化模块】从系统配置文件中读取系统参数和命令行参数,并按照参数来初始化整个系统。
- 然后【连接管理模块】开始监听客户端连接请求,包括TCP/IP以及UnixSocket监听。
- 借助【网络交互模块】,client&server模块“寒暄几句”之后,【连接管理模块】再转发给【线程管理模块】,请求一个连接线程。
- 【线程管理模块】马上又会交给【连接线程模块】,首先连接线程模块会调用【用户模块】进行授权检查。
- 通过权限检查之后,【连接线程模块】会查看连接线程池中是否有被cache的空闲连接线程,如果有就取出一个来给客户端请求占用,如果没有则创建一个新的连接线程。
- 然后是【query解析与转发模块】,对query进行语义和语法解析。
- 如果是select,则调用【查询缓存模块】,如果没命中缓存,则交给【query优化器模块】
- 如果是DML或DDL语句,交给【表变更管理模块】,实际上insert、delete、update、create、alter、这些都有相应的小模块专门负责。
- 各个模块会通过【访问控制模块】检查用户是否具备访问表、字段的权限。
- 如果有权限,【表变更管理模块】通过【表管理模块】获取该表相关的meta信息,根据表的存储引擎,调用【存储引擎接口模块】。至于存储引擎的具体实现,【表变更管理模块】是不感知的。
- 如果是检测、修复、整理类的query,则交给【表维护模块】处理
- 如果是与复制相关的query,则交给【复制模块】去处理
- query执行结束后,控制权交还给连接线程模块,将处理结果通过连接线程返回给客户端。

锁是完全在存储引擎层实现的,所以不同的存储引擎会有不同的锁策略和锁粒度。什么是锁粒度呢?可以简单的理解为,需要锁定的部分的范围。
常见的锁策略有表锁和行锁。这是按照锁粒度去区分的。
显然表锁的粒度更大,并发性能较差,不过CPU的开销小。(上锁也是需要开销的)
而行锁的粒度更小,并发性能较好,但是CPU的开销更大。
假设一种极端的情况,我们需要系统具有最大的并发性。那么,我们在锁策略的选择上就应该选取粒度最小的那种。理想情况就是:
尽量只锁定需要修改的那部分数据。
锁另一种区分方式是:读锁和写锁。
读锁又叫共享锁,比如你的网站的多个用户,是可以同时读取同一个资源的。
写锁又叫排他锁,写锁的特征就是阻塞。当一个用户在修改某条数据时,其他用户是无法获取到读锁或写锁的。
当然服务层的某些行为也会给表上锁,比如当执行alter table时,服务器会给该表上表锁。
事务即一组原子性的sql查询。
常规的概念就不说了,这里只提醒三点:
- 事务也是在存储引擎层实现的
- 事务会带来开销
- 一条sql语句也是一个事务(这里对讲解MVCC会有帮助)
Read Uncommited(未提交读) | Read Commited (提交读) | Repeatable Read (可重复读) | Serializable (可串行化) | |
脏读 | Possible | Not Possible | Not Possible | Not Possible |
不可重复读 | Possible | Possible | Not Possible | Not Possible |
幻行 | Possible | Possible | Possible | Not Possible |
(从上往下依次增加,较低的隔离级别通常支持较高的并发,系统的开销也更低。因为隔离级别是通过影响锁策略和其他机制去实现效果的,上锁是需要开销的)
1.Read Uncommited (未提交读)
事务可以读取未提交的数据,也称脏读。非常可怕,基本不会使用这一级别。
2.Read Commited (提交读)
一个事务从开始到提交之前,所做的修改对其他事务是不可见的。但是重复执行同样的查询可能会导致不同的结果。
3.Repeatable Read (可重复读)
这是mysql的默认隔离级别,重复执行同样的查询结果相同。
4.Serializable (可串行化)
最高的隔离级别,它强制事务串行执行。会导致大量的超时和锁争用问题。虽然数据一致性好,但是并发能力很弱,一般也很少使用。
隔离级别先讲到这里,想讲清楚隔离级别是需要先了解lnnodb的。隔离级别的实现,锁机制的实现,以及事务的实现都是依托于一个核心存储引擎。而无数人的经验告诉我们,innodb在绝大多数情况下都会是最佳的选择。
官方定义:
InnoDB: A transaction-safe (ACID compliant) storage engine for MySQL that has commit, rollback, and crash-recovery capabilities to protect user data. InnoDB row-level locking (without escalation
to coarser granularity locks) and Oracle-style consistent nonlocking reads increase multi-user concurrency and performance. InnoDB stores user data in clustered indexes to reduce I/O for common queries based on primary keys. To maintain data integrity, InnoDB also supports FOREIGN KEY referential-integrity constraints. InnoDB is the default storage engine in MySQL 5.6.
InnoDB:用于MySQL的事务安全(ACID支持)存储引擎,具有提交,回滚和崩溃恢复的功能以保护用户数据。 InnoDB行级锁定(不升级到更粗的粒度锁)和Oracle风格的非锁定读取增加了多用户并发性和性能。 InnoDB将用户数据存储在聚簇索引中,以减少基于主键的常见查询的I / O。 为了保持数据完整性,InnoDB还支持FOREIGN KEY参照完整性约束。 InnoDB是MySQL 5.6中的默认存储引擎。
从这段中,我们能了解的信息很多。支持事务,能崩溃恢复,行级锁,非锁定读,聚簇索引,外键等等
repeatable是mysql默认的隔离级别。它实现了非锁定读nonlocking reads,也可以叫做快照读。
在repeatable下,在一个事务内,如果第一条sql查出了id=10的val='a',那么无论其他事务怎么搞,在这个事务内之后查询100次,都会和第一次一样,返回val='a', 除非你用select for update;
既然不上读锁。意味着在你的这个事务执行时,另一个事务B是可以修改id为10的这条记录的。那么是怎么保证Repeatable Read (可重复读),重复执行同样的查询结果相同。修改之后结果应该不同才对。
MVCC的实现是通过保存数据在某个时间点的快照实现的。正是它的存在,导致nonlocking reads成为可能。
在Innodb中,具体的做法是通过在每行记录后面保存两个隐藏的列。
trx_id和db_roll_ptr, trx_id表示最近修改的事务的id, db_roll_ptr指向undo segment中的undo log。
每次update并且commit这行,这行的trx_id就变大,因为事务id是不断递增的。
一个事务的第一次select,是查询当时的最大trx_id,并且作为此事务的快照trx_id,之后都只会查询每一行小于这个trx_id的row
这样一来,不加读锁就实现了repeatable read隔离级别。