引论
实现人工智能的途径
1、控制论与大脑仿真
2、符号学与亚符号学(符号学派与连接学派?)
符号AI:基于人类易懂的高级符号来表现问题,逻辑和搜索,基于这样一种假设:只能的许多方面能够通过符号操作来获得
例子:专家系统:对规则进行操作来进行推断和确定需要附加什么信息
亚符号学派:符号系统永远无法模仿人类认知的全部过程,基于神经网络、统计学、数值优化等技术
3、逻辑学派与反逻辑学派
逻辑学派:机器无需方阵人类的思考,反倒应该试图去发现抽象推理和问题求解的本质,不管人类是否使用同样的算法
专注使用形式逻辑来解决各种问题,包括只是表征、规划和学习
反逻辑学派:没有简单和通用的原理能够覆盖AI的所有方面,比如视觉和自然语言处理的难题需要特别的解决办法
基于知识学派
在AI应用中构建知识——知识革命,其出现是为了满足简单的AI应用所需要的庞大的知识
4、符号主义和连接主义
符号主义:符号AI凭借符号以及它们之间的关系来表征信息,特定的算法用于处理这些符号并解决问题和推导新的知识
连接主义:连接主义AI用网络内部的一种分布形式来表征信息,在基础学习,任务处理和问题求解方面模仿生物学习过程
5、统计方法
数学工具解决特定的子问题
6、智能Agent范式
理性操作类型的AI,具有动作能力的某样东西,具有自主操作,感知环境,持续动作,顺应变化,实现目标,(在存在不确定性的情况下预测)最佳结果
通过感受器感知外部环境,通过执行器作用于外部环境,通过学习或者应用知识来实现其目标
思考题
哪种方式更好?
理性Agent方式
比“人类思考/行动”的方式更好,一方面精确的推理不是获得理性的唯一可行机制,另一方面理性Agent方式更顺应科技的发展
描述:
1、类似于计算机程序的抽象功能系统
2、抽象智能体,区别于现实世界的计算机系统、生物系统或组织机构
3、自主智能体,强调其自主性
4、理性智能体,借用经济学术语,将目标导向行为作为智能的本质
一系列定义:
1、逐渐顺应新的问题求解规划
2、适合在线与实时
3、能够从行为、错误与成功方面进行自我分析
4、能够与环境交互进行学习与改善
5、迅速从大量的数据中学习
6、具有基于内存的样本存储和检索能力
7、具有表示短期和长期记忆、遗忘等参数
什么是理性Agent?
理性:对于给定的感知序列,能使期待的性能指标最大化
理性所依赖的四件事:
1、定义成功标准的性能指标
2、智能体对环境的先验知识
3、智能体能够完成的动作
4、智能体最新的感知序列
理性Agent能做什么?
一种能在环境中根据感知生成一系列可以导致环境产生一系列符合期望的状态变化的动作的智能体
三要素:环境中依据感知生成动作,这些动作可以导致环境产生一系列状态变化,这些变化是符合期望的
任务环境
PEAS任务环境规范
Performance性能
Environment环境
Actuators动作器
Sensors感受器
任务环境对于智能体而言是“问题”,而智能体则是解决方式
例子:
智能体类型 | Performance | Environment | Actuators | Sensors |
的士司机 | 安全、快速、守法、舒适、收益 | 道路、交通、行人、顾客 | 方向盘、油门、刹车器、信号灯、喇叭 | 摄像头、速度仪、GPS、里程表、加速度计、引擎传感器、操作盘 |
卫星图像分析系统 | 正确的图像归类 | 轨道卫星的下行信道 | 场景归类的显示 | 颜色像素阵列 |
网购者 | 价格、质量、合理性、效率 | 网站、厂商、货主 | 商品显示、跟随URL、填单 | 网页 |
环境类型
1、完全可观测与部分可观测
完全可观测:传感器在每个时间点上都可以访问环境的完整状态
2、单智能体与多智能体
单智能体:一个环境内只有一个智能体在运行
3、确定性与随机性
确定性:环境的下一个状态完全由当前环境的状态以及智能体执行的动作所决定
4、阵发性(Episodic)与顺序性(sequential)
阵发性:智能体的行动的过程被分为原子的片段,每一个片段中选择的动作仅由这个片段决定
5、动态与静态
动态:环境随着智能体的行为而改变
半动态:环境不随着时间推移而改变,但是随着智能体的性能评分的变化而变化
6、离散型与连续型
区别在于环境的状态、处理时间的方式、智能体的感知和动作是离散的还是连续的
7、已知与未知
已知:所有的动作的结果都是给定给的
未知:智能体需要通过学习如何动作以做出正确的决策
例子
环境类型 | 的士司机 | 卫星图像分析系统 | 网购者 |
完全可观测与部分可观测 | 部分可观测 | 完全可观测 | 部分可观测 |
单智能体与多智能体 | 多智能体 | 单智能体 | 单智能体 |
确定性与随机性 | 随机 | 确定 | 随机 |
阵发性(Episodic)与连续性(sequential) | 阵发性 | 阵发性 | 顺序性 |
动态与静态 | 动态 | 半动态 | 半动态 |
离散型与连续型 | 连续 | 连续 | 离散 |
智能Agent的结构
Agent函数——包含各种决策制定规则的抽象概念
实现方法:
1)单个选项的效用计算
2)贯穿逻辑规则的推论
3)模糊逻辑
4)查找表
Agent程序:实现一个智能体的功能,包含Agent函数,将当前的感知作为感受器的输入,返回一个动作给执行器
Agent结构
Agent=platform+Agent program
platform=computer device+sensors+actuators
Agent program\supset Agent function
Agent的层次结构
智能体通常表现为一个分层的结构,它包含许多子智能体
子智能体处理和执行较低级的功能
智能体和子智能体构建一个可以通过行为和反应来完成艰巨任务的完整系统
Agent内部状态的描述
原子方式:每个状态是一个黑盒子,没有内部结构
因子方式:每个状态由一组固定的属性和值组成
结构方式:每个状态包含对象,每个对象具有属性和与其他对象的联系
智能Agent的分类
基于智能Agent感知智能和能力,将智能Agent分为五类:
1)simple reflex agents简单反射智能体
2)model-based reflex agents基于模型的反射智能体
3)goal-based agents基于目标的智能体
4)utility-based agents基于效用的智能体
5)learning agents学习智能体
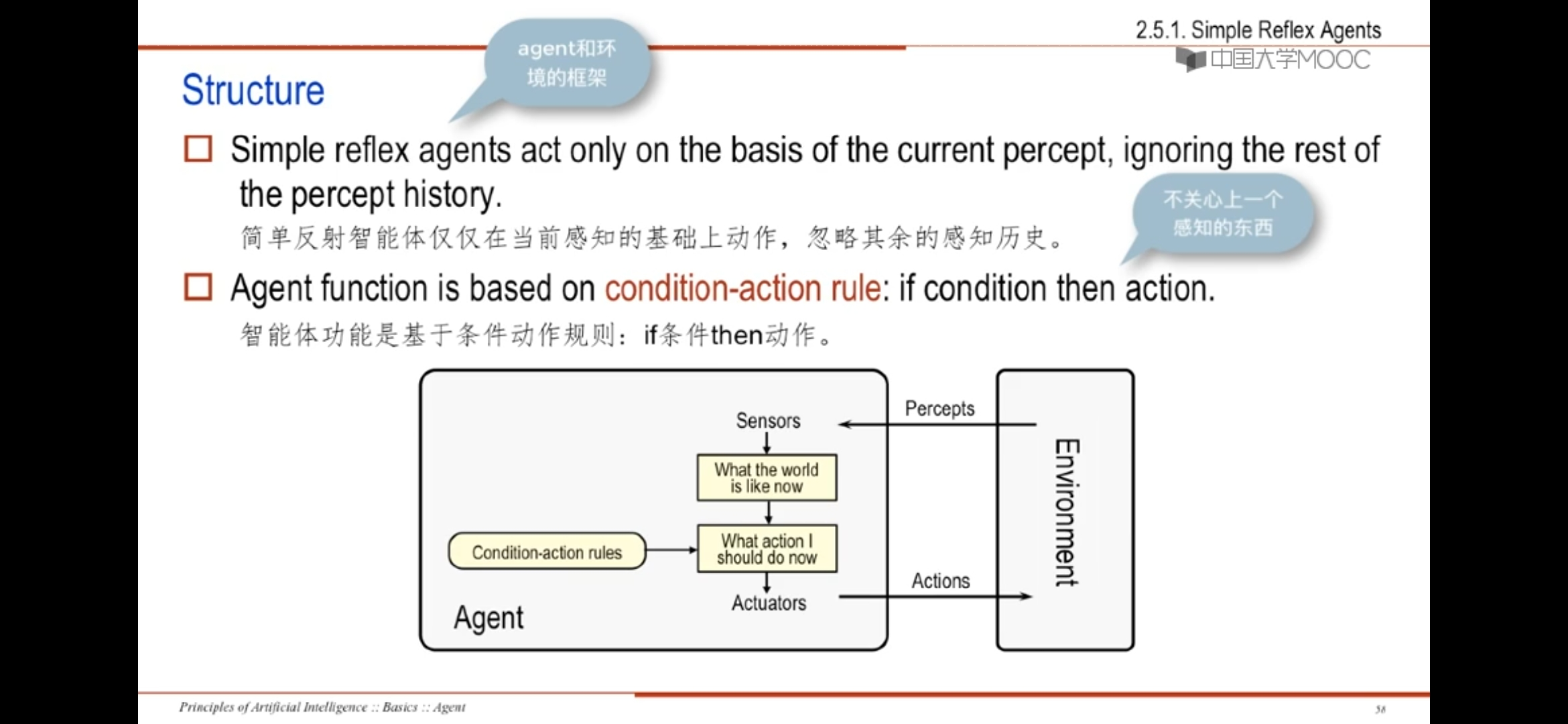
1、simple reflex agents简单反射智能体
1)忽略感知历史,仅仅在当前感知的基础上动作
2)基于条件动作规则:if条件then动作
???性质:
1)仅当外部环境为完全可观测时,该智能体的功能才能发挥
2)某些反射智能体包含其关于当前状态的信息,允许忽视执行器已被触发的条件
3)智能体在部分可观测环境下运行时,无限循环往往是无法避免的
4)若智能体可随机产生其动作,有可能从无限循环中摆脱出来
算法:
function SIMPLE-REFLEX-AGENT(percept) returns an action
persistent: state, the agent's current conception of the world state
rules, a set of condition-action rules
action, the most recent action, initially none
state<-INTERPRET-INPUT(percept)
rule<-RULE-MATCH(state, rules)
action<-rule.ACTION
return action
步骤:
1、状态是Agent对当前外部状态的理解
2、根据条件-动作规则,找出当前状态匹配的动作
3、返回动作,执行器执行,action是最近的动作,初始状态为空
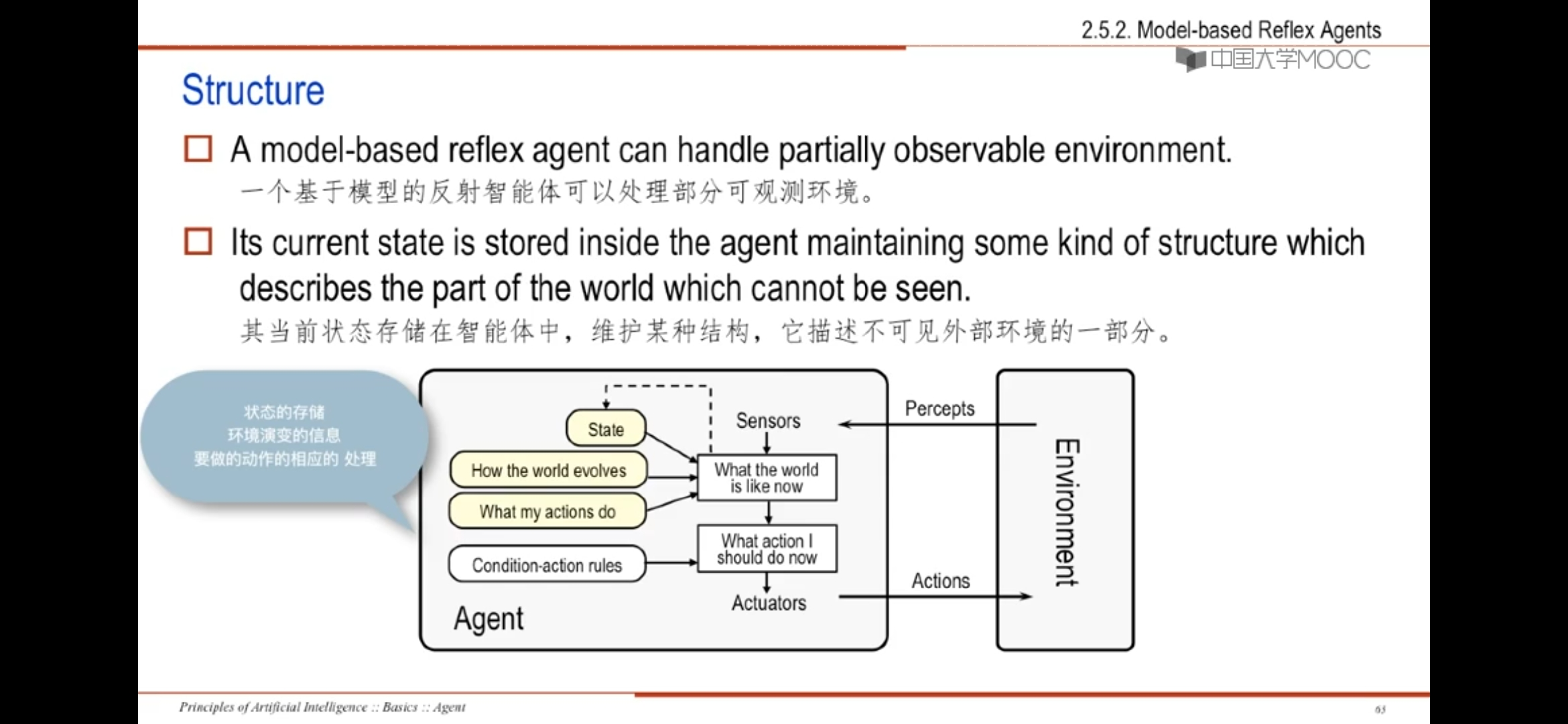
2、model-based reflex agents基于模型的反射智能体
与简单反射Agent的区别:可处理部分可观测环境
Agent结构中增加了状态的存储、环境演变的信息、要做的动作的相应的处理三个部分
其中关于外部环境的部分“How the world workd”被称为外部世界的模型,因此被命名为基于模型的智能体
基于模型的发射智能体能保持某种依赖过去感知历史的,能反映当前状态无法观测的信息的内部模型,基于这种内部模型,以反射智能体的方式选择动作
算法:
function MODEL-BASED-REFLEX-AGENT(percept) returns an action
persistent: state, the agent's current conception of the world state
model, a description of how the next state depends on current state and action
rules, a set of condition-action rules
action, the most recent action, initially none
state<-UPDATE-STATE(state, action, percept, model)
rule<-RULE-MATCH(state, rules)
action<-rule.ACTION
return action
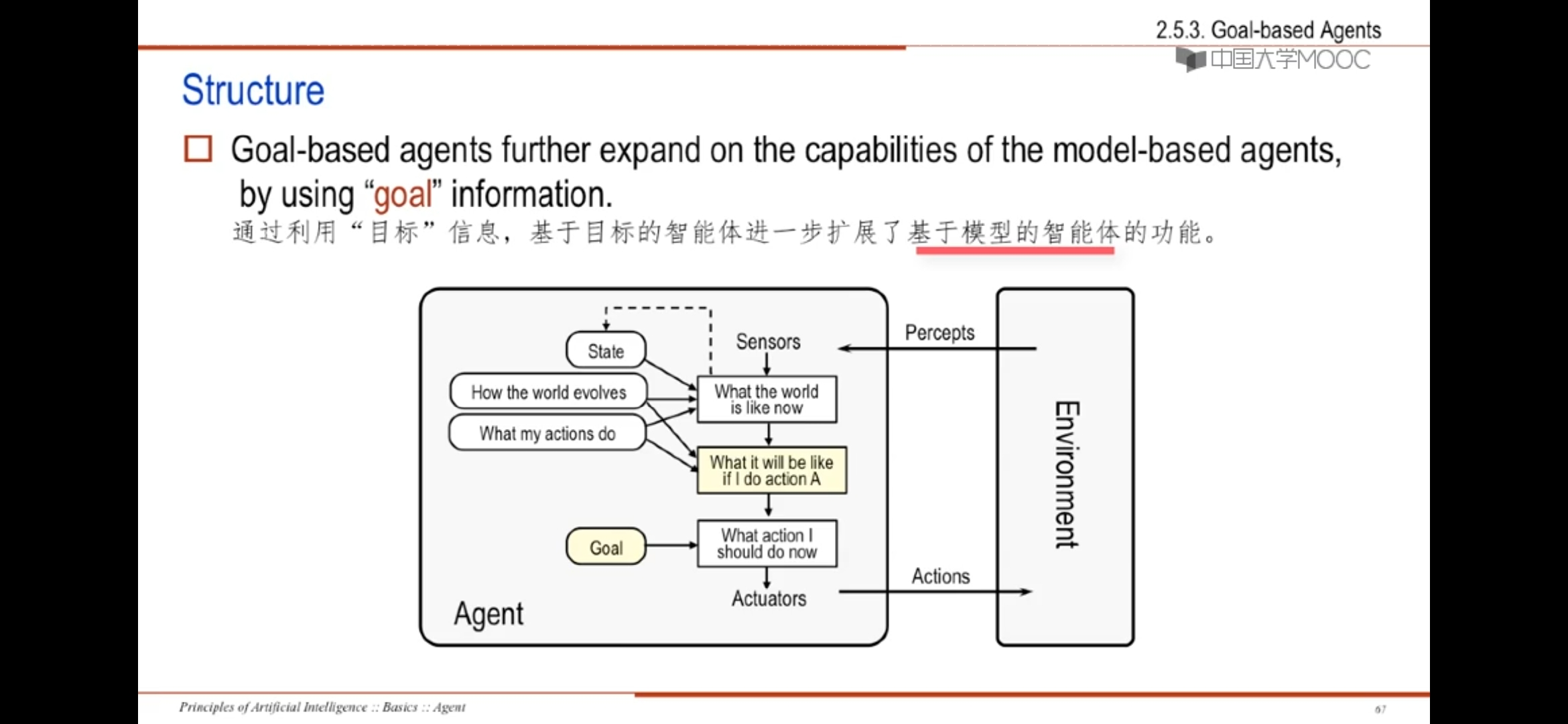
3、goal-based agents基于目标的智能体
拓展了基于模型的智能体的功能,进一步利用了目标信息,来做出动作决策
目标信息描述所希望的情形,智能体可在多克可能性中选择一种方式,挑选出到达目标状态的哪一个
某些情况下基于目标的智能体似乎不太有效,但是它更灵活,因为支持其决策的知识得以更显著地展示出来,并可被修改
与反射Agent不同的是,目标Agent不是通过条件-动作规则,而是通过目标信息做出动作决策的
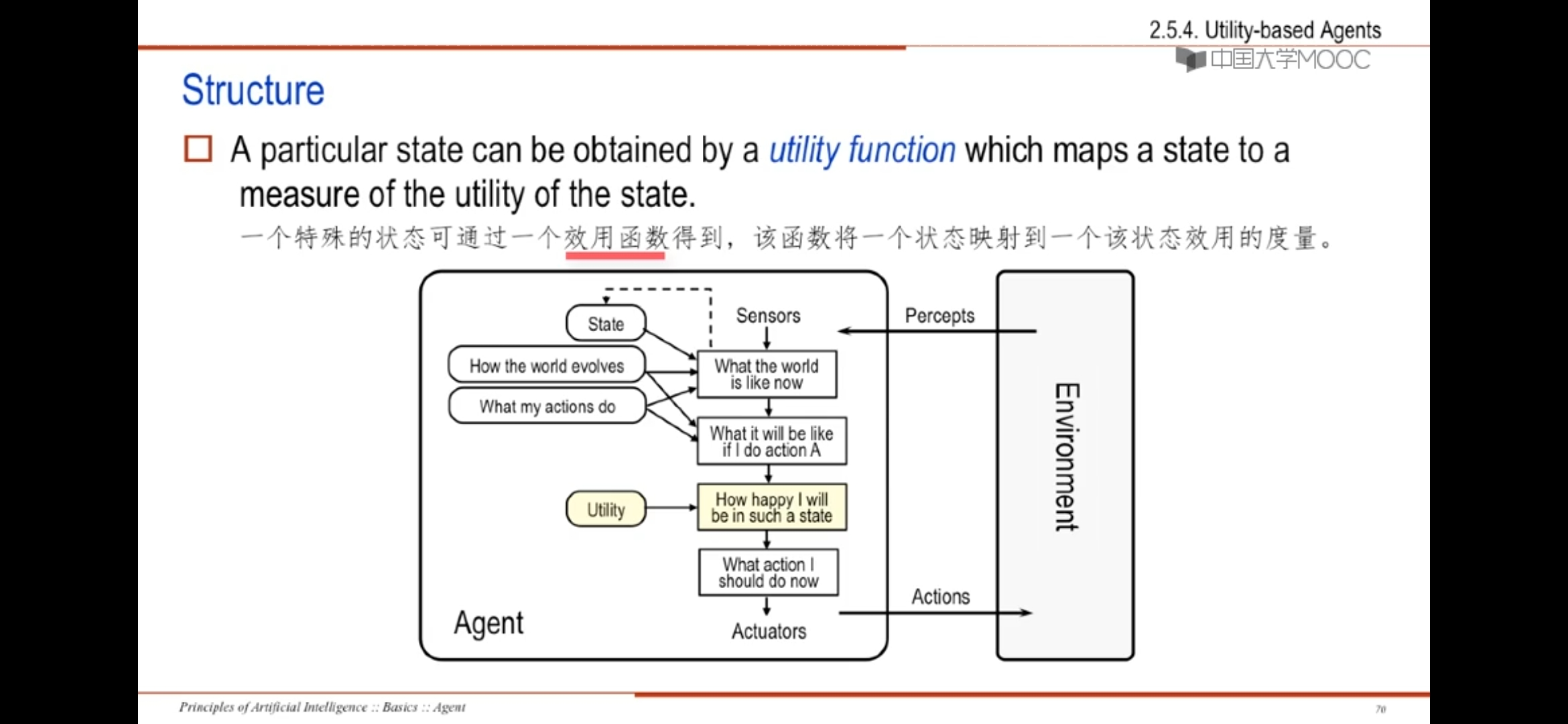
4、utility-based agents基于效用的智能体
一个特定的状态可由一个效用函数得到,该函数将一个状态映射为一个效用量
也是基于模型的智能体的拓展,利用效用函数衡量当前状态的效用值,动作结果期待效用最大化
一个基于效用的智能体需要建模并且记录环境、任务轨迹,这涉及大量的感知、表征、推理和学习的研究
5、learning agents学习智能体
学习允许智能体最初在未知的环境中运行,并且与其最初的知识相比,会越来越胜任
相比于感受器->性能->执行器Agent,增加了批评者,学习模块以及问题生成模块
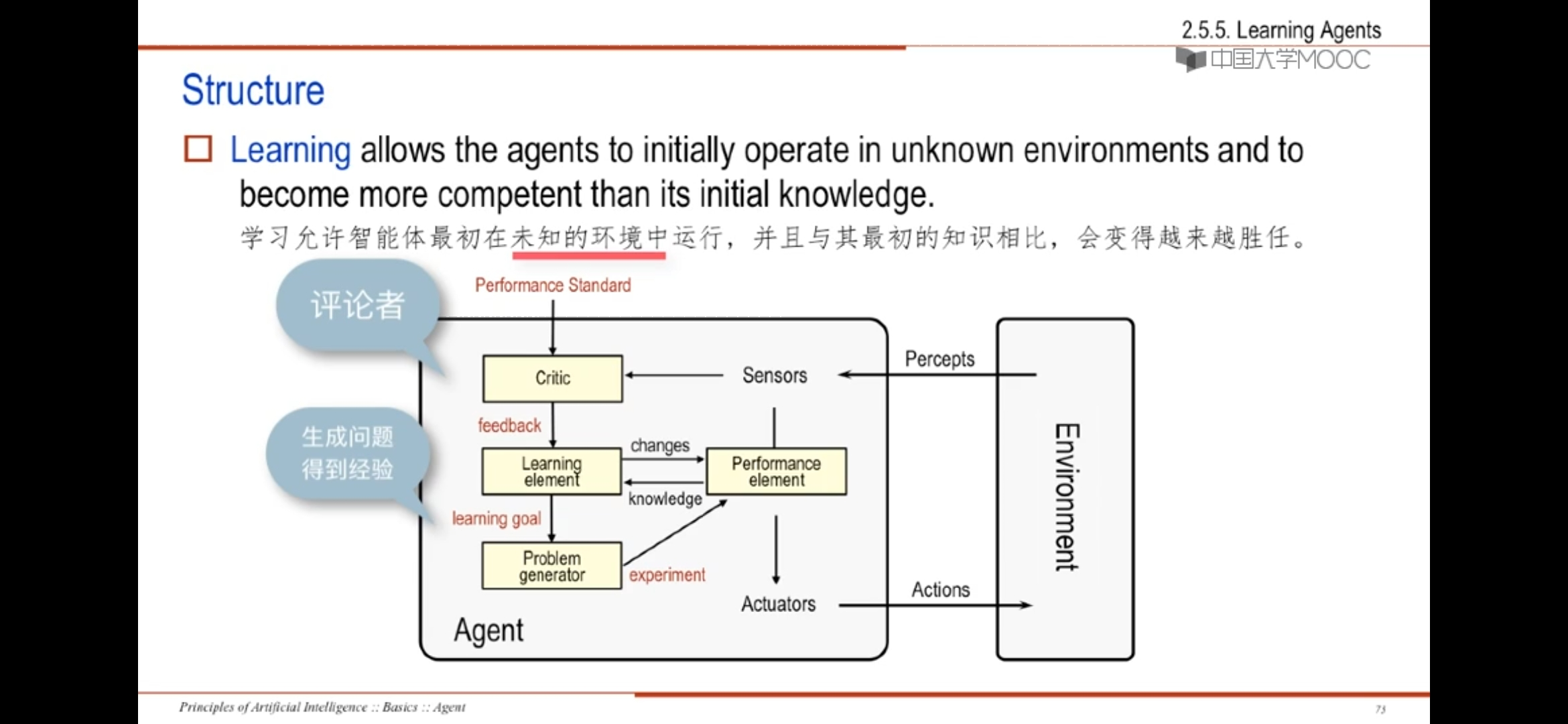
learning element:利用评论者对智能体如何动作的反馈,决定如何修改性能要素以便未来做得更好
performance element:获得感知并决定动作
problem generator:问题发生器,对推荐的动作负责,形成新的经验