第二章模型评估与选择
训练误差training error/经验误差empirical error:学习器在训练集上的误差
泛化误差generalization error:学习器在新样本上的误差
过拟合:学习器把样本自身的一些特点当作了潜在样本都具有的一般性质,导致泛化性能下降
欠拟合:值训练样本的一般性质尚未学好
过拟合是无法彻底避免的
评估方法
通过实验来对学习器的泛化误差进行评估,从而做出选择;这需要从已有的样本中划分训练集和测试集。
训练集中最好不要出现测试集的样本,否则容易得出过于乐观的测试误差。
训练集和测试集的划分回影响训练效果和测试效果。
需要用已有样本,划分训练集和测试集用评估方法对不同的模型进行评估;再根据评估结果选出合适的模型,利用所有已有样本训练出最终模型,最后提交。
留出法
将数据集划分位两个互斥集合,一个用作训练集,一个用作测试集。、
需要注意的是:
1)分层采样,避免划分过程引入额外偏差,保留类别比例
2)要多次随即划分,重复进行实验评估后取平均值作为评估结果
3)训练集和测试集的比例要恰当,常见比例是\frac23\sim\frac45 的样本作为训练集
交叉验证法
步骤:
1)将数据集划分为k个大小相似的互斥子集,通过分层采样尽量保持数据分布的一致性
2)灭磁使用一个子集作为测试集,其余k-1个作为训练集,进行k次训练和测试
3)取k次测试结果的平均值作为最终测试结果
4)为了减小因为样本划分不同而引入的差别,前三步需要随机使用不同的划分重复多次
重复p次的划分k个子集的交叉验证称为p次k折交叉验证
交叉验证法的特例——留一法,即令k=m
优点:绝大多数情况下,被实际评估的模型与期望评估的模型很相似
缺点:数据集较大时,计算开销过大
自助法
留出法和交叉验证法因为样本训练规模不同导致估计偏差,而留一法计算复杂度太高,自助法避免了这两个缺点。
以自主采样法为基础,对于包含m个 样本的数据集D ,进行m 次有放回的采样,得到一个包含m个 样本的训练集D' 。
采用D' 为训练集,D-D' 为测试集,D 中始终不被抽到的样本约占\lim_{m\to\infty}\left(1-\frac1m\right)=\frac1e\approx0.368=36.8\%
这样的测试结果亦称包外估计out-of-bag estimate
自助法在数据集较小、难以有效划分训练集测试集时很有用;但是采集数据的方式改变了数据集的分布,回引入估计偏差。
在初始数据量足够时,留出法和交叉验证法更常用。
性能度量
回归任务的性能度量
回归任务常用的性能度量是“均方误差”mean squared error
E(f;D)=\frac1m\sum_{i=1}^m(f(x_i)-y_i)^2
对于一般的数据分布D 及其概率密度函数p(\cdot) ,均方误差为
E(f;D)=\int_{x\sim D}(f(x)-y)^2p(x)dx
分类任务的性能度量
分类任务常用的性能度量是错误率和精度
错误率定义为E(f;D)=\frac1m\sum_{i=1}^mI(f(x_i)\ne x_i)
精度定义为acc(f;D)=\frac1m\sum_{i=1}^mI(f(x_i)= x_i)=1-E(f;D)
对于一般的数据分布D 及其概率密度p(\cdot) ,错误率为E(f;D)=\int_{x\sim D}I(f(x)\ne y)p(x)dx
精度为acc(f;D)=\int_{x\sim D}I(f(x)=y)p(x)dx=1-E(f;D)
混淆矩阵(分类结果混淆矩阵)
接受 | 拒绝 | |
正例 | TP(真正列) | FN(假反例) |
反例 | FP(假正例) | TN(真反例) |
称拒绝正例为犯第一类错误(拒真错误)
称接受反例为犯第二类错误(取伪错误)
查准率、查全率、[InvalidCharacterError: "S<" did not match the Name production]
查准率(所有接受的之中含有正例的比例)
P=\frac{TP}{TP+FP}
查全率(所有正例中,被接受的比例)
R=\frac{TP}{TP+FN}
理想的P-R曲线
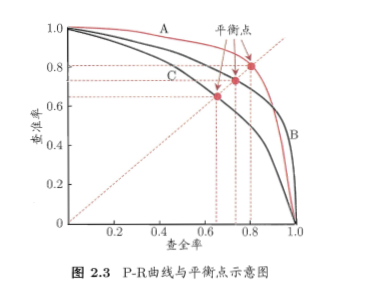
比较方法:
若一个学习器的P-R曲线完全在另一个学习器的P-R曲线的上方,则前者的性能优于后者;
若两者的P-R曲线有交叉,则比较其平衡点,或者曲线与两坐标轴所围成的面积的大小
F_1 度量
由查准率和查全率的调和平均定义,调和平均中,小的值对结果的影响更大
\frac1F_1=\frac1 2\left(\frac1P+\frac1R\right)\Rightarrow
F_1=\frac{2PR}{P+R}
F_\beta 度量
由查准率和查全率的加权调和平均定义
\frac1F_\beta=\frac{1}{1+\beta^2}\left(\frac1P+\frac{\beta^2}R\right)\Rightarrow
F_\beta=\frac{(1+\beta^2)PR}{\beta^2P+R}
宏准率、宏查全率、宏[InvalidCharacterError: "S<" did not match the Name production]
对于多次训练得到的混淆矩阵,分别计算其查准率和查全率,记为(P_1,R_1),(P_2,R_2),...,(P_n,R_n)
宏查准率macro-P=\frac1n\sum_{i=1}^nP_i
宏查全率macro-R=\frac1n\sum_{i=1}^nR_i
宏F_1 macro-F_1=\frac{2\cdot macro-P\cdot macro-R}{macro-P+macro-R}
微查全率、微查准率、微[InvalidCharacterError: "S<" did not match the Name production]
对于多次训练得到的混淆矩阵,计算TP,FN,FP,TN 的平均值,记为\overline{TP},\overline{FP},\overline{FN},\overline{TN}
微查准率micro-P=\frac{\overline{TP}}{\overline{TP}+\overline{FP}}
微查全率micro-R=\frac{\overline{TP}}{\overline{TP}+\overline{FN}}
微F_1 micro-F_1=\frac{2\cdot micro-P\cdot micro-R}{micr-P+micro-R}
真正例率、假正例率
TPR=\frac{TP}{TP+FN} (真正例率)
FPR=\frac{FP}{FP+TN} (假正例率)
ROC曲线与AUC(ROC曲线下方的面积)
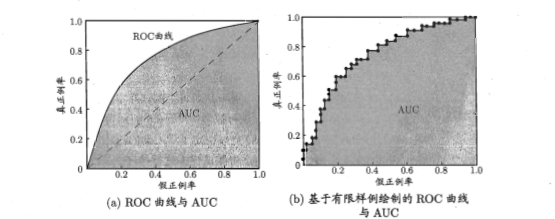
比较方法:
若两条ROC曲线不相交,则位于上方的曲线对应的学习器性能更优;
若两条ROC曲线相交,比较AUC,面积大的所对应的学习器性能更优
AUC计算方法
假设ROC曲线是由坐标为\{(x_1,y_1),...,(x_m,y_m)\} 的点依次连接而成的,则AUC=\sum_{i=1}^{m-1}(x_{i+1}-x_i)(y_{i+1}+y_i)
(注意,任意两个相邻的点,x值和y值有一个是相同的)
AUC(平均)损失的计算
假设预测值相同的正例和反例,排在前后的概率是相等的,都是0.5,则(平均)“损失”定义为
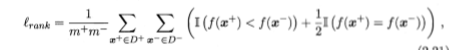
同时(平均)AUC满足
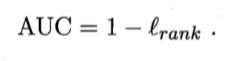
代价敏感错误率
若假正例与假反例的代价不同,则二分类代价矩阵可以表示如下
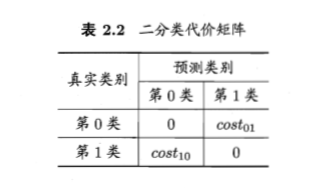
此时的错误率——代价敏感(cost-sensitive)错误率可以表示为
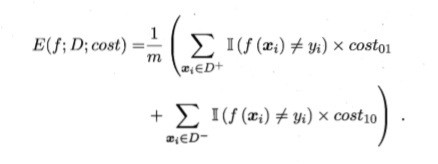
ROC曲线不能反映出代价敏感的特性
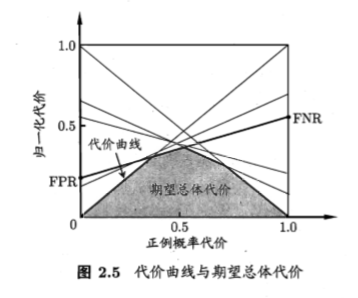
代价曲线
由二分类代价矩阵知,学习器预测错误的期望代价可表示为cost=p\cdot cost_{10}+(1-p)\cdot cost_{01} ,其中p\cdot cost_{10} 是假反例的概率代价,(1-p)\cdot cost_{01} 是假正例的概率代价,则将假反例代价归一化得到\frac{p\cdot cost_{10}}{p\cdot cost_{10}+(1-p)\cdot cost_{01}} ,即(归一化)正例概率代价
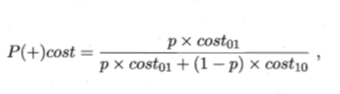
其中p=P\{ 样本为正例| 预测错误\}
归一化代价可以定义为
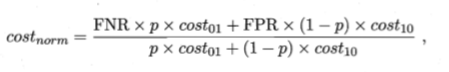
代价曲线的绘制
对于ROC曲线上任意一点对应的FNR和FPR,连接点(0,FPR),(1,FNR) 的线段,得到在当前预测条件下的代价曲线,这条曲线下的面积为当前预测条件下的期望总体代价,所有直线围成的区域的面积为在所有条件下学习器的期望总体代价
检验方法
假设检验
二项检验
设对学习器进行了一次测试,其错误频率为\epsilon ,原假设为\epsilon\le\epsilon_0 ,置信度为1-\alpha ,则有P\{\epsilon\ge\epsilon_0\}<\alpha ,由于P\{\epsilon\ge\epsilon_0\} 关于\epsilon 单调递增,所以估计量应该取可以使P\{\epsilon\ge\epsilon_0\} 最大的值,因此有\hat\epsilon=\arg\max_\epsilon\sum_{i=\epsilon_0 m+1}^mC_m^i\epsilon^i(1-\epsilon)^{m-i}<\alpha
t检验
假设对学习器进行了k次测试,错误率分别为\hat\epsilon_1,...,\hat\epsilon_k ,样本均值和样本方差分别为\mu=\frac1k\sum_{i=1}^k\hat\epsilon_i,\sigma^2=\frac{1}{k-1}\sum_{i=1}^k(\hat\epsilon_i-\mu)^2 ,假设这k个测试错误率可以视作泛化错误率\epsilon_0 的独立采样,则变量\tau_t=\frac{\sqrt k(\mu-\epsilon_0)}{\sigma} 服从自由度为k-1的t分布
则假设\mu=\epsilon_0 的置信度为1-\alpha 的置信区间为[\epsilon_0+\frac{\sigma}{\sqrt k}t_{-\frac\alpha2},\epsilon_0+\frac{\sigma}{\sqrt k}t_{\frac\alpha2}]
交叉验证t检验
对于两个学习器A和B,使用k折交叉验证法得到的测试错误率分别为\epsilon_1^A,...,\epsilon_k^A 和\epsilon_1^B,...,\epsilon_k^B ,使用k折交叉验证“成对t检验”,若两个学习器性能相同,则错误率也应该尽量接近
令\delta_i=\epsilon_i^A-\epsilon_i^B,i=1,2,...,k ,\mu=\frac1k\sum_{i=1}^k\delta_i,\sigma^2=\frac{1}{k-1}\sum_{i=1}^k(\delta_i-\mu)^2 ,则变量\tau_t=\frac{\sqrt k\mu}{\sigma} 服从自由度为k-1 的t分布
则假设\epsilon^A=\epsilon^B 的置信度为1-\alpha 的置信区间为[\pm\frac{\sigma}{\sqrt k}t_{\frac\alpha 2}]
[InvalidCharacterError: "<" did not match the Name production] 交叉验证
每次2折交叉验证之前,随即将数据打乱,使得5次交叉验证中数据划分不重复,第i次第1折和第2折的学习器A和B的错误率的差值为\delta_i^1,\delta_i^2
为了缓解测试错误率的非独立性,仅计算第一次二者交叉验证的两个结果的平均值,但对每次二折实验的结果都计算出其方差\sigma_i^2,i=1,2,3,4,5 ,则变量\tau_t=\frac{\mu}{\sqrt{\frac15\sum_{i=1}^5\sigma_i^2}} 服从自由度为5的t分布,其双边检验的临界值为t_{\frac\alpha2}
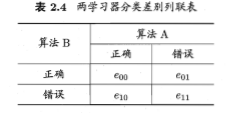
McNemar检验
根据学习器A和B在测试集上的表现,列出列联表
统计量
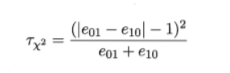
服从自由度为1的\chi^2 分布,给定显著度\alpha ,则临界值为\chi_\alpha^2
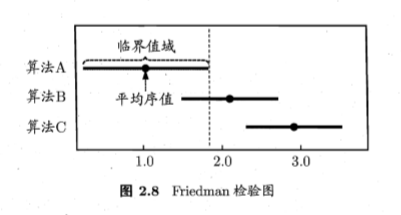
Friedman检验与Nemenyi后续检验
这两种检验方法属于非参数检验,原理细节未知,步骤如下
Friedman检验
对k个学习器在N个数据集上进行测试,按照错误率从小到大排序,并赋予排序值,若两个学习器的性能相同,它们的排序值应为平均值
例子
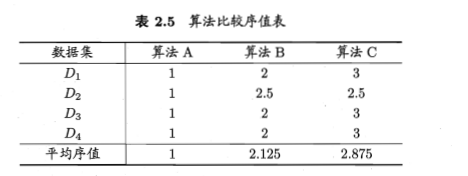
若它们的性能相同,则平均序值应当相同,,令r_i 表示第i个算法的平均序值,则r_i 服从正态分布,其均值和方差分别为\frac{k+1}2,\frac{k^2-1}{12}
构造统计量\tau_{\chi^2}=\frac{k-1}{k}\frac{12N}{k^2-1}\sum_{i=1}^k\left(r_i-\frac{k+1}{2}\right)^2=\frac{12N}{k(k+1)}\left(\sum_{i=1}^kr_i^2-\frac{k(k+1)^2}{4}\right) ,在k与N都充分大时,服从自由度为k-1的\chi^2 分布
也可构造统计量\tau_F=\frac{(N-1)\tau_{\chi^2}}{N(k-1)-\tau_{\chi^2}} ,服从自由度为k-1,(k-1)(N-1) 的F 分布
Nemenyi检验
若“所有算法性能相同”这一假设被拒绝,则说明算法性能显著不相同,采用Nemenyi检验来进行后续检验
Nemenyi检验给出临界值域CD=q_\alpha\sqrt{\frac{k(k+1)}{6N}} ,若两个算法的平均序值差距超过CD,则认为算法性能显著差异,否则认为没有显著不同
Friedman检验图(横线为Nemenyi检验的值域CD)
偏差与方差分析
以回归任务为例,其方差分解为
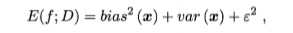
即泛化误差可以分解为偏差、方差和噪声之和
偏差-方差窘境
偏差与方差是有冲突的,即在训练不足时,学习器拟合能力不强,样本的扰动不足以让学习器产生显著变化,因此偏差主导了泛化错误率;随着训练程度的逐渐充分,学习器的拟合能力变强,受到数据变化的影响更显著,此时方差主导泛化错误率