第三章线性模型
线性模型的基本形式
对于由d 个属性描述的示例,线性模型试图学的一个通过属性的线性组合来进行预测的函数,即f(x)=\omega_1x_1+...\omega_dx_d+b ,也可写为f(x)=\omega^Tx+b
线性回归
目标:
基本的线性回归
给定数据集D=\{(x_1,y_1),...,(x_d,y_d)\} ,线性回归任务试图学得一个线性模型以尽可能准确地预测实值输出标记,即试图学得f(x_i)=\omega^Tx_i+b,s.t.f(x_i)\approx y_i
模型:
对数线性回归
将输出标记的对数作为线性模型逼近的目标,即\ln y=\omega^Tx+b ,即让e^{\omega^Tx+b} 逼近y
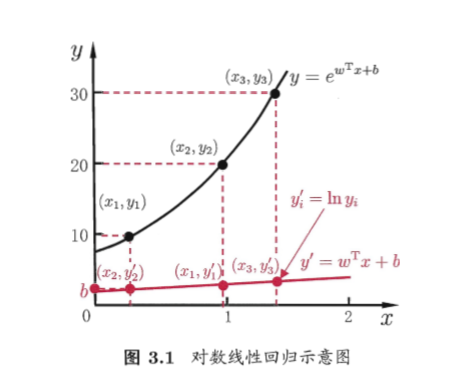
广义线性模型
更一般地可以考虑单调可微函数g(\cdot) ,令y=g^{-1}(\omega^Tx+b) ,这样的模型称为广义线性模型,其中函数g(\cdot) 称为联系函数
对数几率回归(对率回归)
对于二分类任务,考虑对数几率函数y=\frac{1}{1+e^{-z}},z=\omega^Tx+b
对数几率函数可将z=\omega^Tx+b 转化为一个接近0或1的y值,其输出值在z=0附近变化很陡
对数几率函数可以变形为\ln \frac{y}{1-y}=\omega^Tx+b ,若将y视为样本为正例的可能性,则1-y为反例的可能性,则\frac{y}{1-y} 为正例可能性与反例可能性的比例,称为几率(odds),因而\ln\frac{y}{1-y} 称为对数几率
求解:
最小二乘法
线性判别分析
任务:
给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异类样例的投影点尽可能远离。对新样例进行预测使,根据投影点的未知来确定新样本的类别。
模型:
给定数据集D=\{(x_i,y_i)\}_{i=1}^m,y_i\in\{0,1\} ,令X_i,\mu_i,\Sigma_i 分别表示第i\in\{1,0\} 类样例的集合、均值向量、协方差矩阵。若将数据投影到直线\omega上 ,两类样本中心在直线上的投影分别为\omega^T\mu_0,\omega^T\mu_1 ,若将所有样本都投影到直线上,则两类样本的协方差分别为\omega^T\Sigma_0\omega,\omega^T\Sigma_1\omega
为了使同类样例尽量接近,所以要使\omega^T\Sigma_0\omega+\omega^T\Sigma_1\omega 尽量小;为了使不同类样本尽量远离,所以要使||\omega^T\mu_0-\omega^T\mu_1||_2^2 尽量大,因此有目标函数J=\frac{||\omega^T\mu_0-\omega^T\mu_1||_2^2}{\omega^T\Sigma_0\omega+\omega^T\Sigma_1\omega}=\frac{||\omega^T\mu_0-\omega^T\mu_1||_2^2}{\omega^T(\Sigma_0+\Sigma_1)\omega} ,
目标是求\omega ,使得J 最大
求解:
拉格朗日乘子法,广义特征值问题
多分类学习
二分类学习可推广到多分类,将多分类任务拆分为若干个二分类任务求解,然后将这些二分类任务学习器的预测结果集成以获得最终的多分类结果
拆分策略:OvO,OvR,WvW
OvO,将类别两两配对,产生\frac{N(N-1)}{2} 个二分类任务,分别求解;对于新样本的分类结果由各个学习器的投票结果产生
OvR,将一个类别作为正例,其余作为反例,训练N个分类器;对于新样本,若只有一个分类器预测为正类,则取其结果作为最终分类结果,否则取多个分类器的预测置信度最大的那个预测结果
MvV,采用ECOC编码思想来进行类别划分
二元ECOC距离:
Hamming距离\frac12\sum_i|a_i-f_i|,a_i,f_i\in\{1,-1\}
欧氏距离\left[\sum_i(a_i-f_i)^2\right]^\frac12,a_i,f_i\in\{1,-1\}
三元ECOC距离:
Hamming距离\frac12\sum_i|a_i-f_i|,a_i,f_i\in\{1,0,-1\}
欧氏距离\left[\sum_i(a_i-f_i)^2\right]^\frac12,a_i,f_i\in\{1,0,-1\}
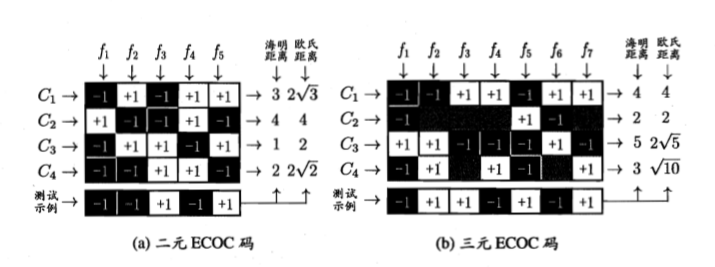
对于预测结果,取最近的一个类别作为其分类
由于不同类别的编码不同,且其距离较大,因而ECOC码具有了一定的纠错能力
不能通过暴力搜索计算出最优编码,因为这是NP难问题
码长不能无限长,因为类别的组合是有限的,所以过长的码长除了会增加计算复杂度以外是无意义的
类别不平衡问题