提问解答练习
什么是欠拟合?什么是过拟合?
欠拟合:对训练样本的一般性质尚未学好
过拟合:把训练样本自身的一些特点当作了所有潜在样本都具有的一般性质
有无可能彻底避免过拟合?为什么?
不可能。机器学习面临的问题一般都是NP难的,而有效的学习算法必然是在多项式时间内运行完成。如果存在有效的学习算法可以彻底避免过拟合,则通过经验误差最小化即可获得最优解,即意味着构造性地证明了P=NP 。因此只要相信P\ne NP ,过拟合就不可避免。
如何评估模型?
模型的泛化误差越小,模型越好。但是实际中无法直接取得泛化误差,因此使用一个测试集,以测试集上的测试误差作为泛化误差的近似。
如何从给定的数据集中分割出训练集与测试集?
1)留出法
多次随机分层采样,将数据集分割为互斥且互补的训练集和测试集,常见做法是2/3~4/5作为训练集
2)交叉验证法
多次将训练集划分为k份,k次训练,每份都拿来做一次测试集,剩余的都拿来做训练集
特例是留一法,但是开销大
3) 自助抽样法
有放回重复采样,抽到的样本作为训练集,余下的作为测试集,在数据集较小,难以有效划分训练集测试集时使用
缺点:改变了初始数据的分布,会引入估计误差
度量性能的指标有哪些?
均方误差E(f;D)=\frac1m \sum_{i=1}^m(f(x_i)-y_i)^2
错误率E(f;D)=\frac1m\sum_{i=1}^mI(f(x_i)\ne y_i)
精度acc(f;D)=\frac1m\sum_{i=1}^mI(f(x_i)=y_i)
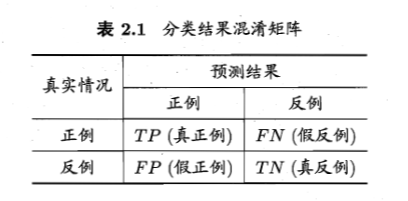
查准率P:P=\frac{TP}{TP+FP}
查全率R:R=\frac{TP}{TP+FN}
F_1 :F_1=\frac{1}{\frac12\frac1P+\frac12\frac1R}
F_\beta :F_\beta=\frac{1}{\frac{\beta^2}{1+\beta^2}\frac{1}{R}+\frac{1}{1+\beta^2}\frac{1}{P}}
进行n次训练测试,得到n个二阶混淆矩阵,则有
宏查准率macro-P:macro-P=\frac1n\sum_{i=1}^nP_i
宏查全率macro-R:macro-R=\frac1n\sum_{i=1}^nR_i
宏F_1 :macro-F_1=\frac{1}{\frac12\frac1{macro-P}+\frac12\frac1{macro-R}}
微查准率micro-P:micro-P=\frac{\overline{TP}}{\overline{TP} +\overline{FP}}
微查全率micro-R:micro-R=\frac{\overline{TP}}{\overline{TP}+\overline{FN}}
微F_1 :micro-F_1=\frac{1}{\frac12\frac1{micro-P}+\frac12\frac1{micro-R}}
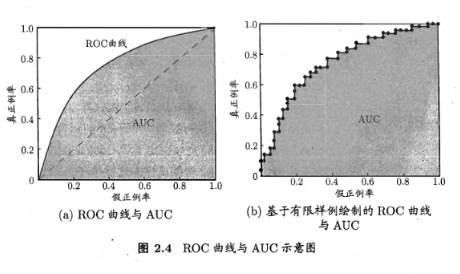
ROC曲线与AUC
真正例率:TPR=\frac{TP}{TP+FN}
假正例率:FPR=\frac{FP}{FP+TN}
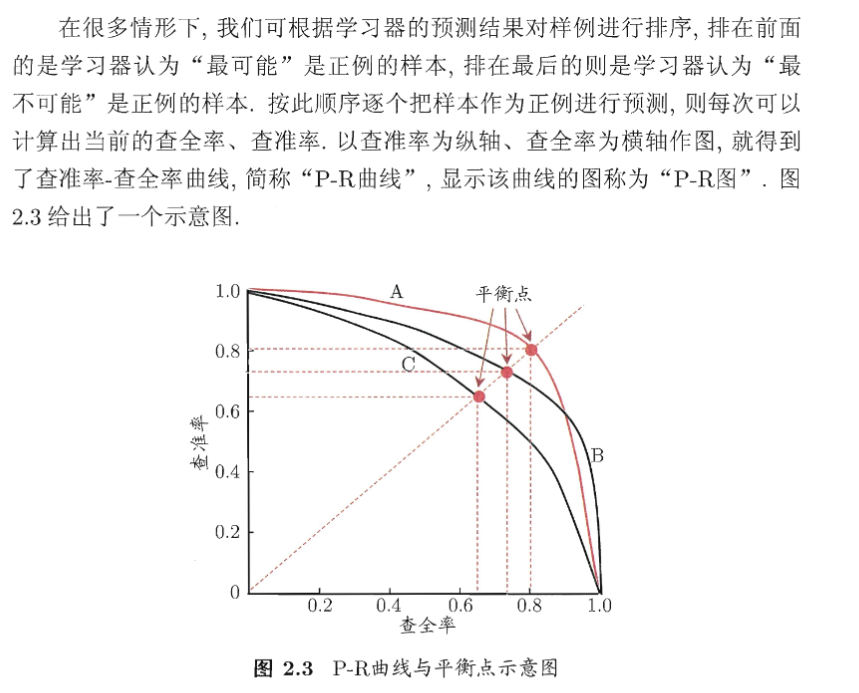
如何绘制P-R曲线与ROC曲线?
P-R曲线纵轴是查准率P=\frac{TP}{TP+FP} ,横轴是查全率R=\frac{TP}{TP+FN} ,将学习器预测后的样本按照预测值从小到大排序,预测值越大越有可能是正例,在m+1个位点之间划分正反例,确定每一点的查准率和查全率
ROC曲线纵轴是真正例率TPR=\frac{TP}{TP+FN} ,横轴是假正例率FPR=\frac{FP}{FP+TN} ,将样本按照学习器的预测值从大到小排序,预测值越大越有可能是正例,以m+1个位点分割正反例,从(0,0)开始,确定ROC曲线。若位点的上一个样本是正例,y=y+\frac{1}{m^+} ,若是反例,x=x+\frac{1}{m^-}
什么是代价敏感问题?如何衡量代价敏感问题中学习器的错误率?
代价敏感问题是将正例判定为反例和将反例判定为正例的代价不一样的问题
如何理解正例概率代价和归一化代价?
如何理解代价曲线和期望总体代价?
假设检验在衡量学习器性能上的作用?
比较检验用于比较两个学习器的性能,假设检验是检验对学习器泛化错误率分布的某种判断或者猜想。
常见的假设检验方法?
二项检验、t-检验、交叉验证t-检验、McNemar检验、Friedmen检验、Nemenyi后续检验
二项检验
假设:\epsilon\le\epsilon_0 (泛化错误率\epsilon 不大于\epsilon_0 )
则置信度为1-\alpha 的置信区间应该这样构造:\hat\epsilon=\arg \max_\epsilon P\{N\le\epsilon_0M\}=\arg \max_\epsilon\sum_{i=0}^{\epsilon_0M}C_M^i\epsilon^i(1-\epsilon)^{M-i}\ge1-\alpha
P\{N<=\epsilon_0M\}\ge1-\alpha
注意:及时\epsilon\le\epsilon_0 ,也有可能N>\epsilon_0M
t-检验
假设:\mu=\epsilon_0 (泛化错误率\mu 等于\epsilon_0 )
则置信度为1-\alpha 的置信区间应该这样构造:P\{-t_{\frac\alpha2}\le \tau_t\le t_{\frac\alpha2}\}\ge1-\alpha ,其中\tau_t=\frac{\sqrt k(\mu-\epsilon_0)}{\sigma},\mu=\frac1k\sum_{i=1}^k\hat\epsilon_i,
\sigma^2=\frac1{k-1}\sum_{i=1}^k(\hat\epsilon_i-\mu)^2 ,\hat\epsilon_i,i=1,...,n 为k个测试错误率
交叉验证t-检验
使用k折交叉验证法得到学习器A、B的测试错误率分别为\epsilon_1^A,...,\epsilon_k^A,\epsilon_1^B,...,\epsilon_k^B ,用成对t检验进行比较检验
假设:\epsilon^A=\epsilon^B (两个学习器性能相同)
则置信度为1-\alpha 的置信区间应该这样构造P\{-t_{\frac\alpha2}\le \tau_t\le t_{\frac\alpha2}\}\ge1-\alpha ,其中
\tau_t=\left|\frac{\sqrt k\mu}{\sigma}\right|,
\mu=\frac1k\sum_{i=1}^k\Delta_i,
\sigma^2=\frac1{k-1}\sum_{i=1}^k(\Delta_i-\mu)^2,
\Delta_i=\epsilon_i^A-\epsilon_i^B,i=1,...,n
由于样本有限,所以不能保证测试错误率为泛化错误率的独立采样,因此需要减小不同轮次训练集重叠带来的影响,采用5次2折交叉验证
构造统计量\tau_t=\frac{\mu}{\sqrt{0,2\sum_{i=1}^5\sigma_i^2}} 服从自由度为5的t分布,其中\mu=0.5(\Delta_1^1+\Delta_1^2),
\sigma_i^2=(\Delta_i^1-\frac{\Delta_i^1+\Delta_i^2}{2})^2+(\Delta_i^2-\frac{\Delta_i^1+\Delta_i^2}{2})^2
McNemar检验
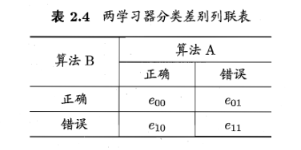
假设:e_{01}=e_{10} (两个学习器性能相同)
变量\tau_{X^2}=\frac{(|e_{01}-e_{10}|-1)^2}{e_{01}+e_{10}} 服从自由度为1的X^2 分布
置信度为1-\alpha 置信区间由P\{\tau_{X^2}\le X_\alpha^2\}\ge1-\alpha 确定
Friedman检验
对一组数据集上的多个算法进行比较
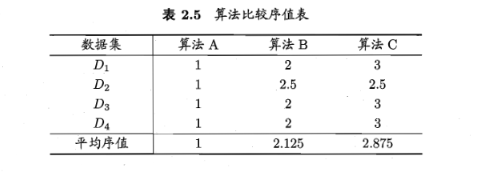

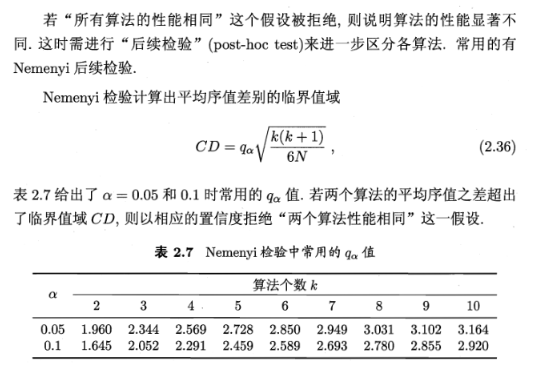
Nemenyi后续检验
A Tutorial on Data Reduction: Linear Discriminant Analysis, Technical Report, Computer Vision and Image Processing Laboratory
Applied Mathematics: Body and Soul, Volume 1: Derivatives and Geometry in IR3
A tutorial on principal component analysis
A tutorial on independent component analysis
A tutorial on support vector regression, Statistics and Computing
偏差-方差分析