面试题
- hashmap底层实现
JDK1.8中对Hashmap做了以下改动。 默认初始化容量=0 引入红黑树,优化数据结构 将链表头插法改为尾插法,解决1.7中多线程循环链表的bug 优化hash算法 resize计算索引位置的算法改进 先插入后扩容
- 二叉树 AVL ,红黑树
二叉树,左小右大红黑树具体有哪些规则特点呢?具体如下: 节点分为红色或者黑色。 根节点必为黑色。 叶子节点都为黑色,且为 null。 连接红色节点的两个子节点都为黑色(红黑树不会出现相邻的红色节点)。 从任意节点出发,到其每个叶子节点的路径中包含相同数量的黑色节点。 新加入到红黑树的节点为红色节点。 查询性能略微逊色于AVL树,因为他比avl树会稍微不平衡最多一层,也就是说红黑树的查询性能只比相同内容的avl树最多多一次比较,但是,红黑树在插入和删除上完爆avl树, avl树每次插入删除会进行大量的平衡度计算,而红黑树为了维持红黑性质所做的红黑变换和旋转的开销,相较于avl树为了维持平衡的 开销要小得多
Q0:HashMap是如何定位下标的?
A:先获取Key,然后对Key进行hash,获取一个hash值,然后用hash值对HashMap的容量进行取余(实际上不是真的取余,而是使用按位与操作,原因参考Q6),最后得到下标。
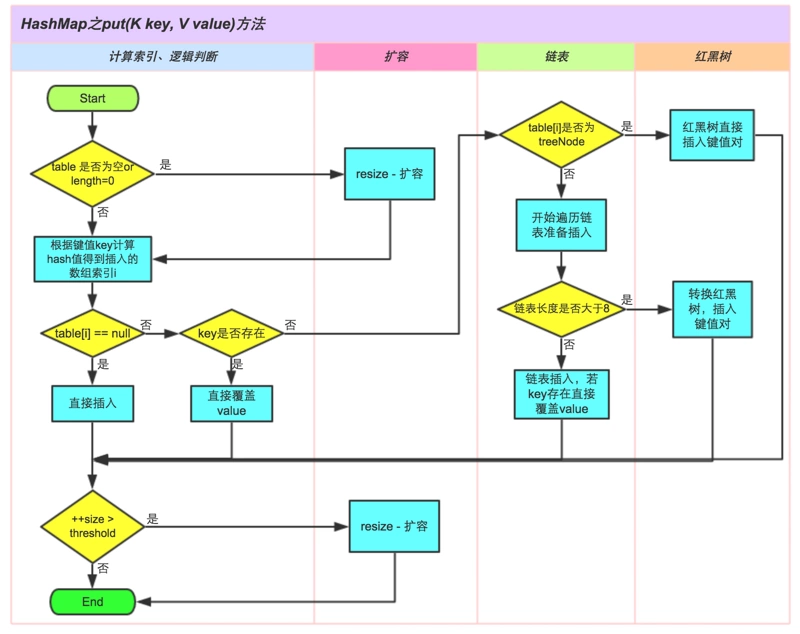
Q1:HashMap由什么组成?
A:数组+单链表,jdk1.8以后又加了红黑树,当链表节点个数超过8个(m默认值)以后,开始使用红黑树,使用红黑树一个综合取优的选择,相对于其他数据结构,红黑树的查询和插入效率都比较高。而当红黑树的节点个数小于6个(默认值)以后,又开始使用链表。这两个阈值为什么不相同呢?主要是为了防止出现节点个数频繁在一个相同的数值来回切换,举个极端例子,现在单链表的节点个数是9,开始变成红黑树,然后红黑树节点个数又变成8,就又得变成单链表,然后节点个数又变成9,就又得变成红黑树,这样的情况消耗严重浪费,因此干脆错开两个阈值的大小,使得变成红黑树后“不那么容易”就需要变回单链表,同样,使得变成单链表后,“不那么容易”就需要变回红黑树。
Q2:Java的HashMap为什么不用取余的方式存储数据?
A:实际上HashMap的indexFor方法用的是跟HashMap的容量-1做按位与操作,而不是%求余。(这里有个硬性要求,容量必须是2的指数倍,原因参考Q6)
Q3:HashMap往链表里插入节点的方式?
A:jdk1.7以前是头插法,jdk1.8以后是尾插法,因为引入红黑树之后,就需要判断单链表的节点个数(超过8个后要转换成红黑树),所以干脆使用尾插法,正好遍历单链表,读取节点个数。也正是因为尾插法,使得HashMap在插入节点时,可以判断是否有重复节点。
Q4:HashMap默认容量和负载因子的大小是多少?
A:jdk1.7以前默认容量是16,负载因子是0.75。
Q5:HashMap初始化时,如果指定容量大小为10,那么实际大小是多少?
A:16,因为HashMap的初始化函数中规定容量大小要是2的指数倍,即2,4,8,16,所以当指定容量为10时,实际容量为16。
A:如果HashMap容量比较小而hash值比较大的时候,哈希冲突就容易变多。基于HashMap的indexFor底层设计,假设容量为16,那么就要对二进制0000 1111(即15)进行按位与操作,那么hash值的二进制的高28位无论是多少,都没意义,因为都会被0&,变成0。所以哈希冲突容易变多。那么hash(Obeject k)方法中在调用 k.hashCode()方法获得hash值后,进行的一步运算:h^=(h>>>20)^(h>>>12);有什么用呢?首先,h>>>20和h>>>12是将h的二进制中高位右移变成低位。其次异或运算是利用了特性:同0异1原则,尽可能的使得h>>>20和h>>>12在将来做取余(按位与操作方式)时都参与到运算中去。综上,简单来说,通过h^=(h>>>20)^(h>>>12);运算,可以使k.hashCode()方法获得的hash值的二进制中高位尽可能多地参与按位与操作,从而减少哈希冲突。
Q10:哈希值相同,对象一定相同吗?对象相同,哈希值一定相同吗?
A:不一定。一定。
Q11:HashMap的扩容与插入元素的顺序关系?
A:jdk1.7以前是先扩容再插入,jdk1.8以后是先插入再扩容。
Q12:HashMap扩容的原因?
A:提升HashMap的get、put等方法的效率,因为如果不扩容,链表就会越来越长,导致插入和查询效率都会变低。
Q13:jdk1.8引入红黑树后,如果单链表节点个数超过8个,是否一定会树化?
A:不一定,它会先去判断是否需要扩容(即判断当前节点个数是否大于扩容的阈值),如果满足扩容条件,直接扩容,不会树化,因为扩容不仅能增加容量,还能缩短单链表的节点数,一举两得。