Redis
- redis 是什么?都有哪些使用场景?
热点数据的缓存
限时业务的运用
计数器相关问题
排行榜相关问题
分布式锁
延时操作
分页、模糊搜索
点赞、好友等相互关系的存储
队列
- 180.redis 有哪些功能?
- 181.redis 和 memecache 有什么区别?
- 182.redis 为什么是单线程的?
redis 核心就是 如果我的数据全都在内存里,我单线程的去操作 就是效率最高的,为什么呢,因为多线程的本质就是 CPU 模拟出来多个线程的情况,这种模拟出来的情况就有一个代价,就是上下文的切换,对于一个内存的系统来说,它没有上下文的切换就是效率最高的。redis 用 单个CPU 绑定一块内存的数据,然后针对这块内存的数据进行多次读写的时候,都是在一个CPU上完成的,所以它是单线程处理这个事。在内存的情况下,这个方案就是最佳方案
- 183.什么是缓存穿透?怎么解决?
缓存穿透又称缓存击穿,是指在高并发场景下缓存中(包括本地缓存和Redis缓存)的某一个Key被高并发的访问没有命中,此时回去数据库中访问数据,导致数据库并发的执行大量查询操作,对DB造成巨大的压力。
解决方法:
1:对缓存失效的Key加分布式锁,当一个Key在本地缓存以及Redis缓存中未查询到数据,此时对Key加分布式锁访问db,如果取到数据就反写到缓存中,避免大量请求进入DB;如果取不到数据则缓存一个空对象,这样可以保证db不会被大量请求直接挂掉,从而引起缓存颠簸,更甚者缓存雪崩效应。
2:在本地缓存一个set集合,存储对应数据为空的key的集合,在请求前做拦截,此种方式牵涉到数据变更还要校验set集合的问题,一般适用于数据更新比较少的场景。
3:使用布隆过滤器
将所有可能存在的数据哈希到一个足够大的bitmap中, 一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
告诉你存在,可能并不存在, 告诉你不存在,一定不存在
- 缓存雪崩
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
加锁排队. 限流-- 限流算法.
- 缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
让缓存永不过期
- 184.redis 支持的数据类型有哪些?
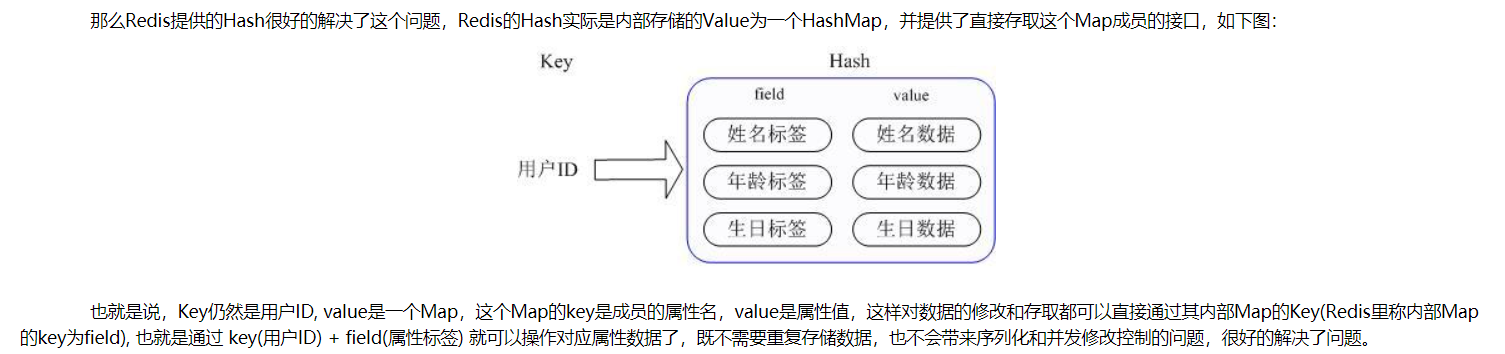
Redis支持5种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
list 就是链表,相信略有数据结构知识的人都应该能理解其结构。使用List结构,我们可以轻松地实现最新消息排行等功能。List的另一个应用就是消息队列,
可以利用List的PUSH操作,将任务存在List中,然后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作List中某一段的api,你可以直接查询,删除List中某一段的元
应用场景:Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
使用场景:Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。和Set相比,Sorted Set关联了一个double类型权重参数score,使得集合中的元素能够按score进行有序排列,redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。比如一个存储全班同学成绩的Sorted Set,其集合value可以是同学的学号,而score就可以是其考试得分,这样在数据插入集合的时候,就已经进行了天然的排序。另外还可以用Sorted Set来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
- 185.redis 支持的 java 客户端都有哪些?
- 186.jedis 和 redisson 有哪些区别?
- 187.怎么保证缓存和数据库数据的一致性?
对删除缓存进行重试,数据的一致性要求越高,我越是重试得快。
定期全量更新,简单地说,就是我定期把缓存全部清掉,然后再全量加载。
给所有的缓存一个失效期。
- 188.redis 持久化有几种方式?
一种是RDB持久化(原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化),另外一种是AOF(append only file)持久化(原理是将Reids的操作日志以追加的方式写入文件)
- 189.redis 怎么实现分布式锁? https://blog.csdn.net/shuangyueliao/article/details/89344256
比如Redis分布式锁,一般就是用Redisson框架就好了,非常的简便易用。
现在某个客户端要加锁。如果该客户端面对的是一个redis cluster集群,他首先会根据hash节点选择一台机器。
紧接着,就会发送一段lua脚本到redis上,那段lua脚本如下所示: 保证这段复杂业务逻辑执行的原子性。
KEYS[1]代表的是你加锁的那个key,比如说:
RLock lock = redisson.getLock("myLock");
这里你自己设置了加锁的那个锁key就是“myLock”。好了,到此为止,ok,加锁完成了。
- 190.redis 分布式锁有什么缺陷?
其实上面那种方案最大的问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。
但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
- 191.redis 如何做内存优化?
- 192.redis 淘汰策略有哪些?
- 193.redis 常见的性能问题有哪些?该如何解决?
redis 集群扩展,hash一致性算法 解决