组件、概念
Presto是一个分布式SQL查询引擎,处理大数据GB到PB秒查询的场景。
Presto不是数据库,是基于数据源的查询引擎。数据源可以是HDFS,Hive,MySQL,OSS等。
优点:
- 清晰的架构,是一个能够独立运行的系统,不依赖于任何其他外部系统。例如调度,presto自身提供了对集群的监控,可以根据监控信息完成调度。
- 简单的数据结构,列式存储,逻辑行,大部分数据都可以轻易的转化成presto所需要的这种数据结构。
- 丰富的插件接口,完美对接外部存储系统,或者添加自定义的函数。
- 基于内存运算,速度快。
- 能够连接多个数据源,实现跨数据源连表查看。例如实现hive和mysql的关联。
缺点:
- 不是把所有pb级的数据都放到内存运算,是根据场景的,例如大量的count,是边读数据边聚合,再清理内存,再读数据再聚合,可能会产生大量的临时文件,速度变慢。
- 过于吃内存。
- HBase支持不好。
Presto架构:
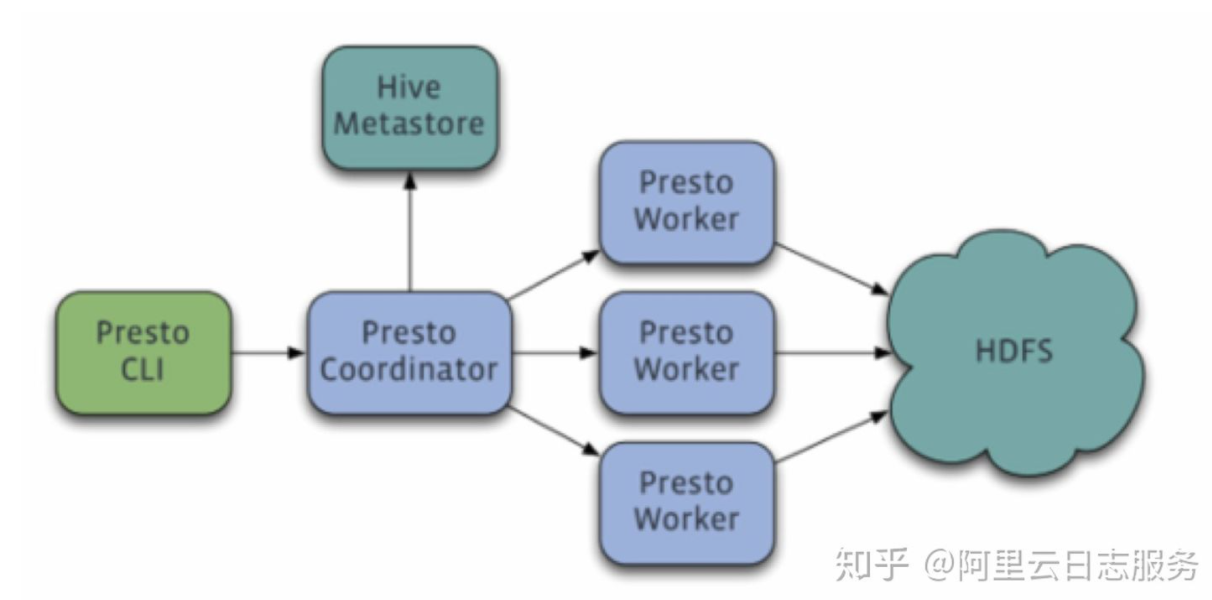
- coordinator(master)负责meta管理,worker管理,query的解析和调度。
- worker则负责计算和读写。
- discovery server,通常内嵌于coordinator节点中,也可以单独部署,用于节点心跳。在下文中,默认discovery和coordinator共享一台机器。