知识抽取&挖掘
知识抽取
从不同来源、不同结构的数据中进行知识提取,形成知识存入到知识图谱。
将非结构化转化为结构化数据
- Schemas
- Relations
- Knowledge base
- RDF triples
- 从结构化数据库中获取知识:D2R
- 难点:复杂表数据的处理
- 从链接数据中获取知识:图映射
- 难点:数据对齐
- 从半结构化(网站)数据中获取知识:使用包装器
- 难点:方便的包装器定义方法,包装器自动生成、更新与维护
- 从文本中获取知识:信息抽取
- 难点:结果的准确率与覆盖率
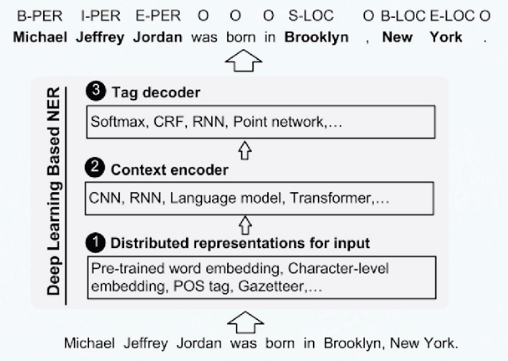
命名实体识别:从文本中识别实体边界及其类型
- 检测:SPO
- 分类:具体类别
识别方法
基于模板和规则
- 优点:准确,有些实体识别只能依靠规则抽取
- 缺点:
- 需要大量的语言学知识
- 需要谨慎处理规则之间的冲突问题;
- 构建规则的过程费时费力、可移植性不好
基于序列标注
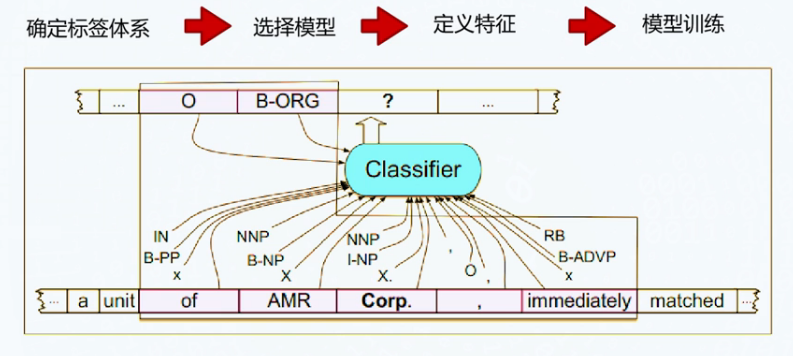
人工特征:
- 词本身的特征
- 边界特征:边界词概率
- 词性
- 依存关系
- 前后缀特征
- 字本身的特征
- 是否是数字
- 是否是字符
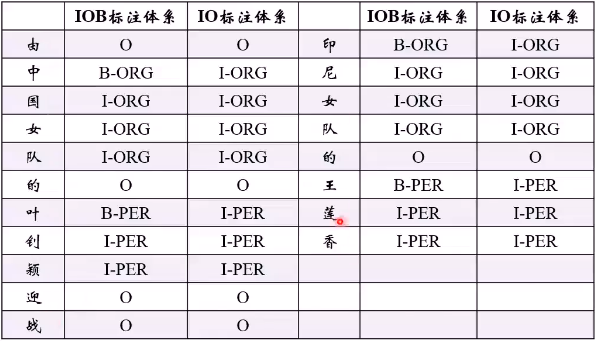
实现方法
HMM(隐马尔科夫模型)
- 有向图
- 生成式模型:找到使P(X,Y)最大的参数
- 马尔可夫性:特征之间是独立的
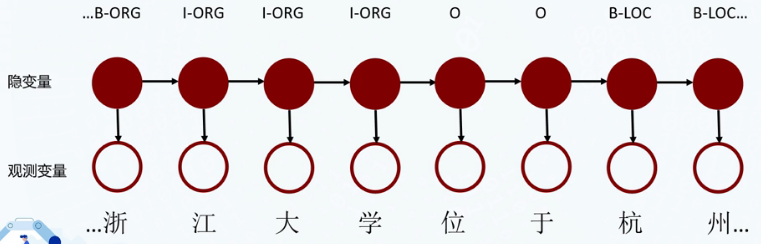
- 隐藏状态集合Q,对应所有可能的标签集合,大小为N
- 观测状态集合V,对应所有可能的词的集合,大小为M
- 对于一个长度为T的序列,
- l对应状态序列(即标签序列),
- O对应观测序列(即词组成的句子)
- 状态转移概率矩阵A=[aij]N*N:转移概率是指某一个隐藏状态(如标签“B-Per”)转移到下一个隐藏状态(如标签“I-Per”)的概率。例如,B-ORG标签的下一个标签大概率是l-ORG,但一定不可能是l-Per
- 发射概率矩阵B=[bj(k)]N*M:指在某个隐藏状态(如标签“B-Per")下,生成某个观测状态(如词“陈”)的概率
- 隐藏状态的初始分布П=[T(i)]N,这里指的是标签的先验概率分布
计算问题:
- 评估观察序列概率:给定模型λ=(A,B,Ⅱ)和观测序列O(如一句话“浙江大学位于杭州”),计算在模型λ下观测序列O出现的概率P(O|λ),这需要用到前向后向算法

- 模型参数学习问题:即给定观测序列O,估计模型入的参数,使该模型下观测序列的条件概率P(O|λ)最大。这个问题的求解需要用到基于EM算法的鲍姆-韦尔奇算法


- 预测问题:也称为解码问题,即给定模型λ和观测序列O,求最可能出现的对应的隐藏状态序列(标签序列),这个问题的求解需要用到基于动态规划的维特比算法

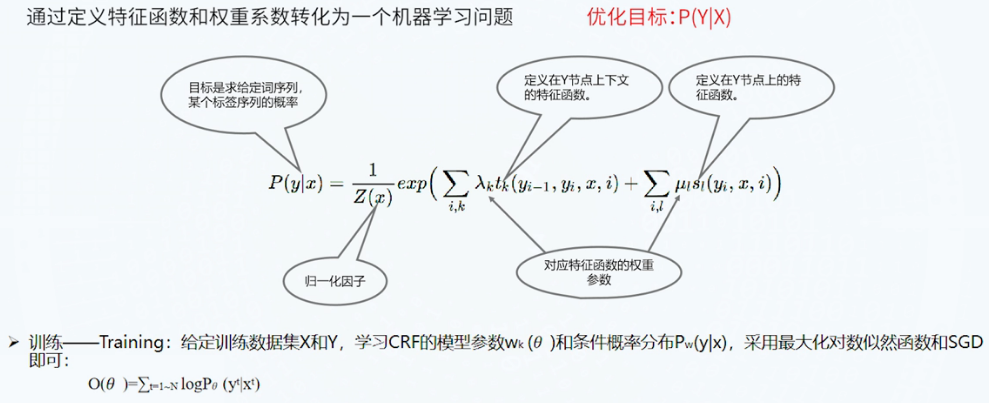
CRF(条件随机场)
随机场包含多个位置,每个位置按某种分布随机赋予一个值,其全体就叫做随机场。
- 马尔科夫随机场假设随机场中某个位置的赋值仅与和它相邻位置的赋值有关,和不相邻位置的赋值无关
- 条件随机场进一步假设马尔科夫随机场中只有X和Y两种变量,X一般是给定的,而Y一般是在给定X的条件下的输出
- 无向图
- 判别式模型:找到使P(X|Y)最大的参数
- 没有特征之间是独立的假设
基于机器学习的实体识别
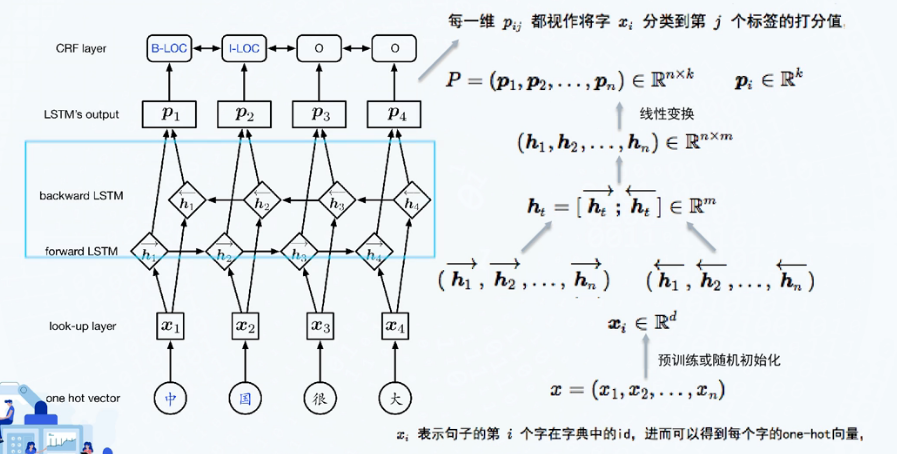
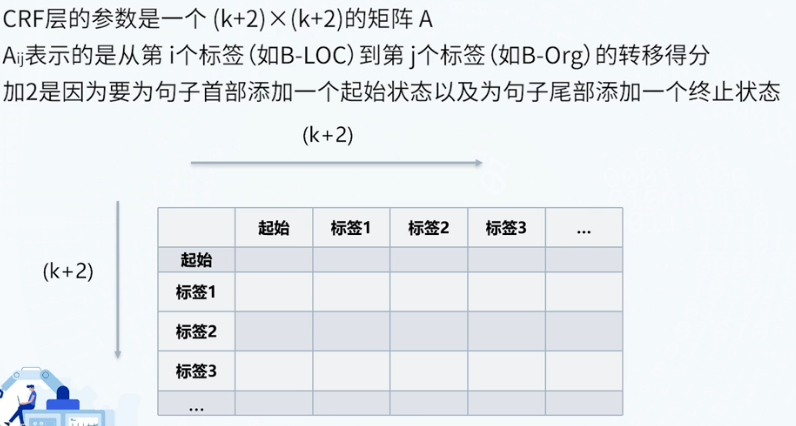
BiLSTM+CRF

基于预训练语言模型的实体识别
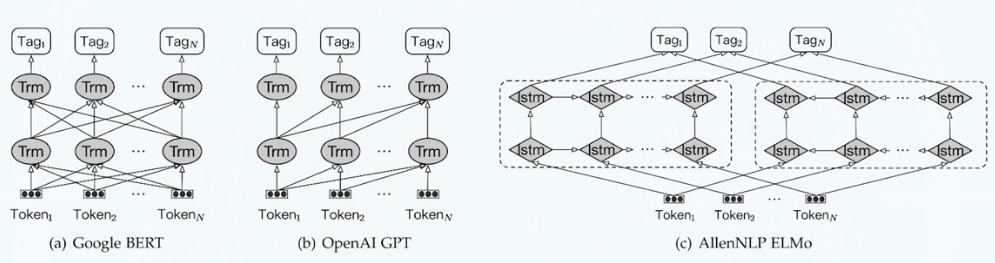
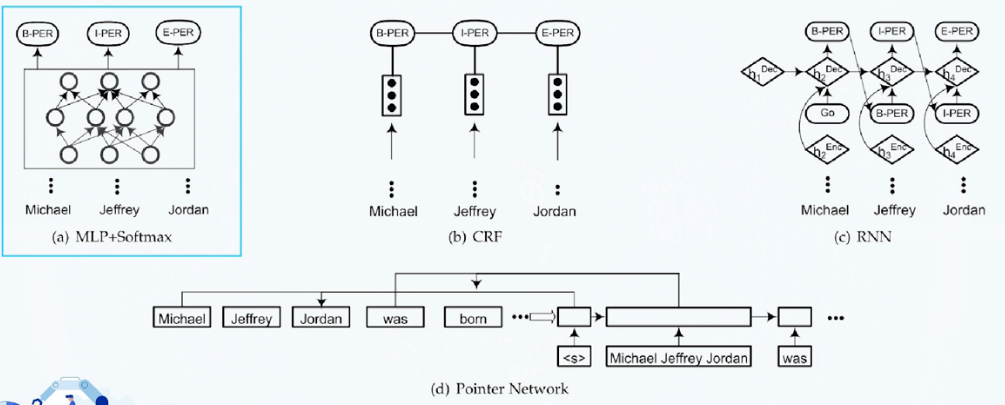
实体识别解码策略
术语抽取(概念抽取):从语料中发现多个单词组成的相关术语
关系抽取
从文本中抽取出两个或者多个实体之间的语义关系,从文本获取知识图谱三元组的主要技术手段。
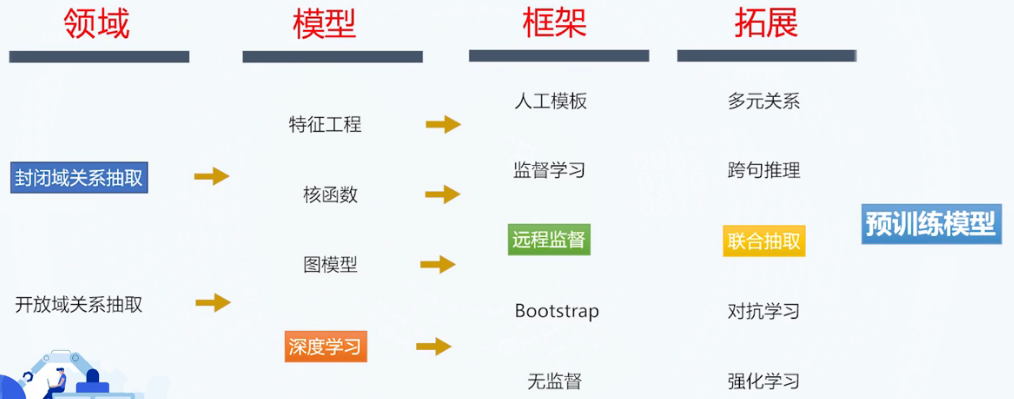
抽取方法
基于模板的方法
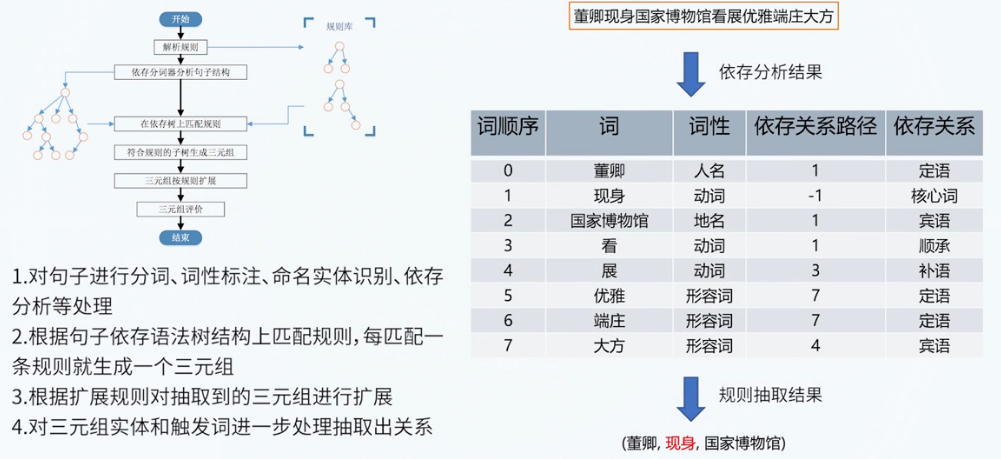
- 基于触发词匹配的关系抽取
- 基于依存句法匹配的关系抽取
- 优点:
- 在小规模数据集上容易实现
- 构建简单
- 缺点:
- 特定领域的模板需要专家构建
- 难以维护
- 可移植性差
- 规则集合小的时候,召回率很低
基于监督学习的关系抽取
- At-least-one Hypothesis:如果2个实体存在关系,则至少有1个句子描述其关系
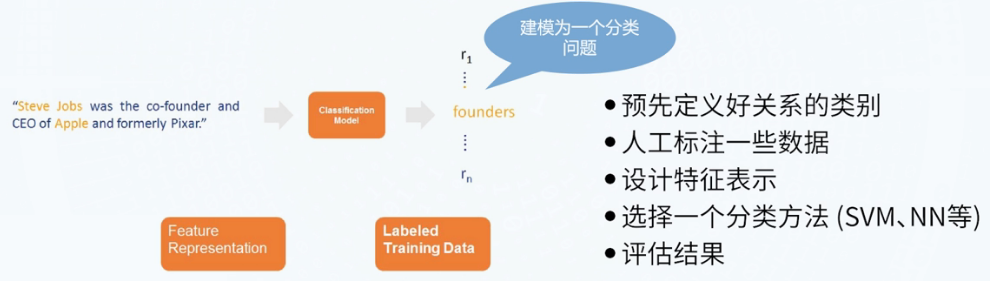
- 特征设计
- 实体特征
- 实体前后的词
- 实体的类型、语法、语义信息
- 实体词的共现特征,e.g.,dog and cat
- 引入外部语义关系, e.g.
- ACE entity types
- WordNet features
- 关系特征
- 实体之间的词
- 窗口及Chunk序列
- 实体间的依存关系路径
- 实体间树结构的距离
- 特定的结构信息,如最小子树
- 实体特征
- 机器学习框架:
- 特征函数+最大熵模型
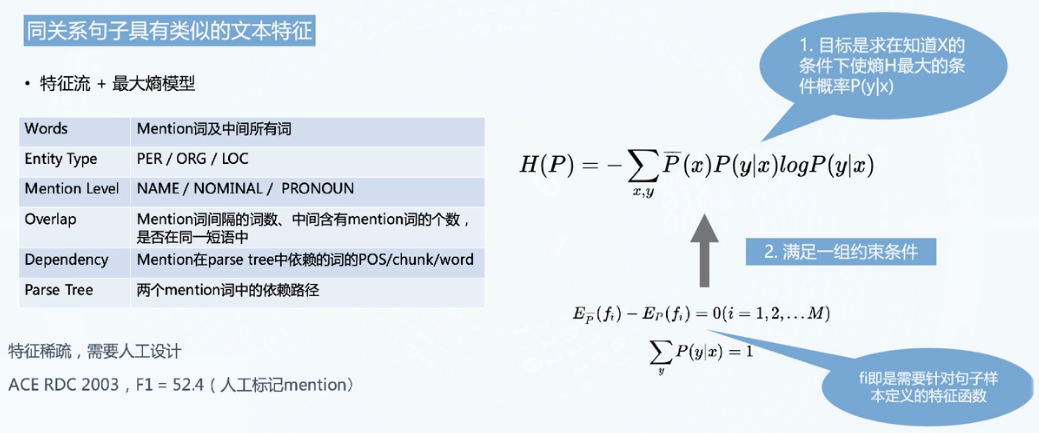
最大熵模型:认为熵最大最好
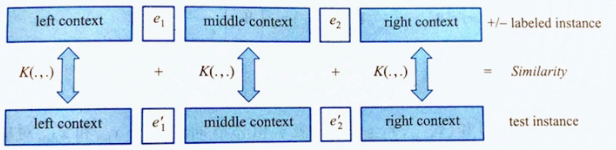
字符串核函数
- 给定带有关系标注的训练样本集合,该方法首先基于每个样本中出现的实体e1和e2将该样本切分为左端上下文left、中间上下文middle和右端上下文right三部分
- 给定测试样本,根据其中出现的实体e1'和e2'对其进行同样的切分,生成left'、middle'和right'
- 基于字符串核函数计算该样本与每个训练样本在上述三个上下文上的相似度
- 最后对三个相似度得分进行加和,并用于分类模型的训练与预测
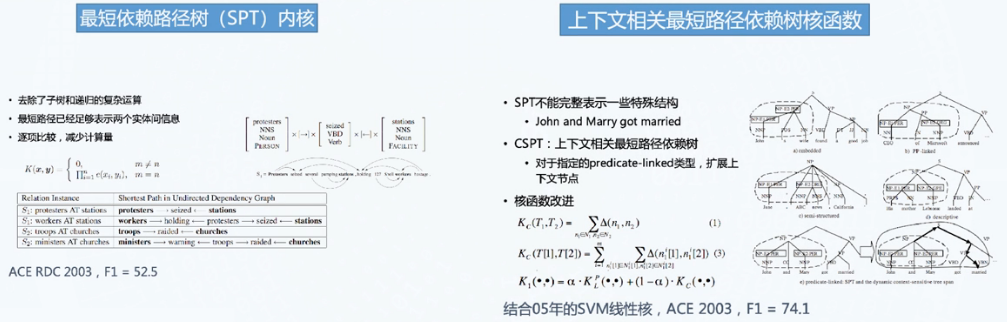
句法树核函数

最短依赖路径树核函数
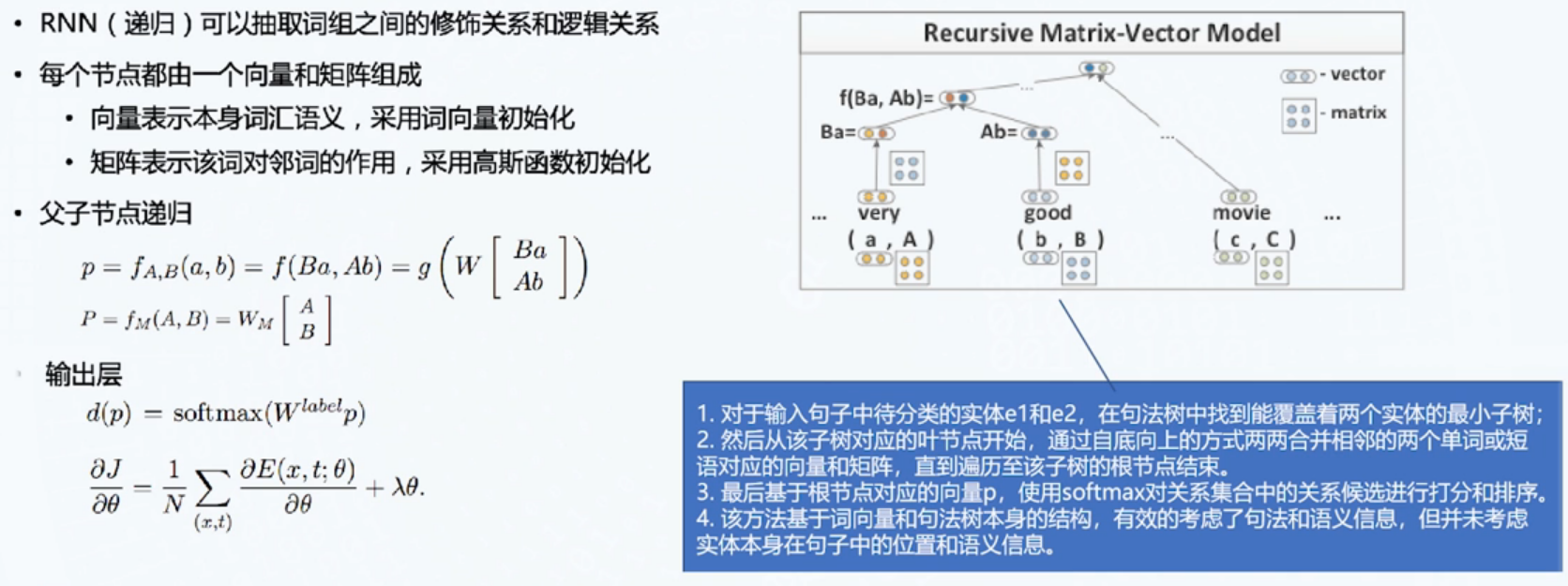
递归神经网络RNN
CNN


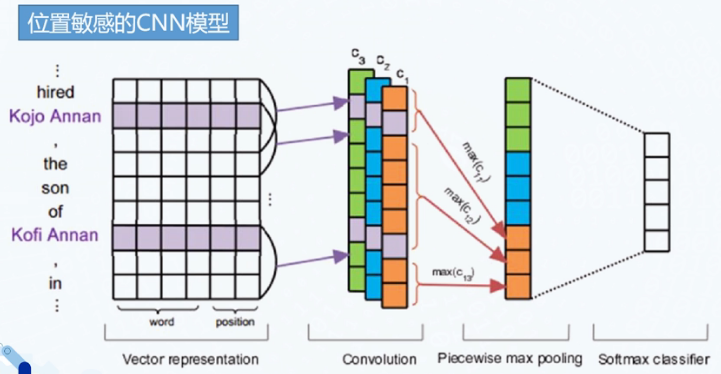
位置敏感的CNN(PCNN)
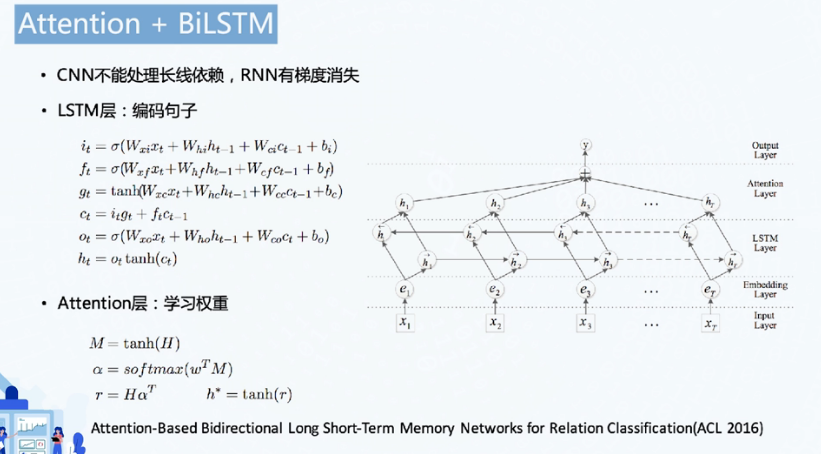
BiLSTM
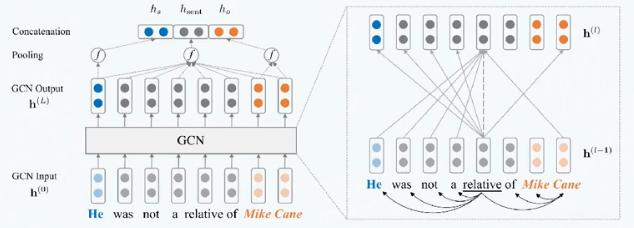
图神经网络
图神经网络在图像领域的成功应用证明了以节点为中心的局部信息聚合同样可以有效的提取图像信息
利用句子的依赖解析树构成图卷积中的邻接矩阵,以句子中的每个单词为节点做图卷积操作。如此就可以抽取句子信息,再经过池化层和全连接层即可做关系抽取的任务
拓展问题