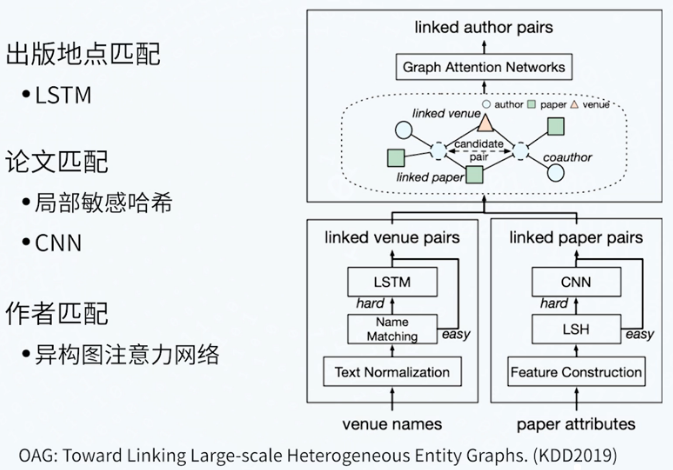
知识图谱融合
知识融合是解决知识图谱异构问题的有效途径。
知识融合的核心问题在于映射的生成。
知识融合的作用
- 数据清洗
- 构建的知识图谱存在异构性
- 知识融合是重要的预处理步骤之一
- 数据集成
- 不同知识图谱可能存在重叠的知识
- 融合多个不同来源的知识图谱
异构问题


本体匹配(Ontology Matching)
- 发现(模式层)等价或相似的类、属性或关系
- 本体对齐、本体映射
本体匹配发现一个三元组M=[InvalidCharacterError: "O,O'" did not match the Name production],包括一个源本体О ,一个目标本体O',以及一个映射单元集合M ={m1,mz,... mn}。其中mi表示一个基本映射单元,可以写成mi =[InvalidCharacterError: "ID,C," did not match the Name production]的四元组形式:
- id为映射单元的标识符,用于唯一标识该四元组
- c和c'分别为О和O'中的概念
- s表示c和c'之间的相似度,满足s∈[0,1]
本体:领域知识规范的抽象和描述,是表达、共享、重用知识的方法
- 真实世界的模型
- 术语集
- 术语的含义
- 形式化逻辑:一阶谓词逻辑
术语匹配方法
基于字符串:直接比较表示本体成分的术语的字符串结构规范化
- 大小写:字符串中的每个符号转换为大写字母或小写字母的形式
- 消除变音符:Montreal替换为Montreal;
- 空白正规化:所有的空白字符(如空格、制表符和回车等)转换为单个的空格符
- 连接符正规化:正规化单词的换行连接符等
- 消除标点:在不考虑句子的情况下要去除标点符号
- 消除无用词:如“to”和“a”
- 相似度
- Levenshtein距离,即最小编辑距离,目的是用最少的编辑操作将一个字符串转换成另一个
- 汉明距离,它计算两个字符中字符出现位置的不同
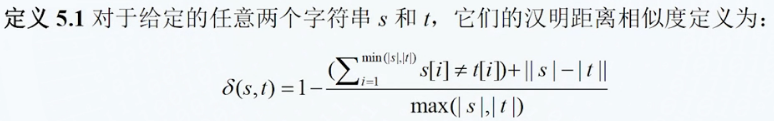

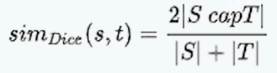
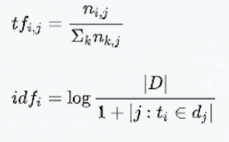
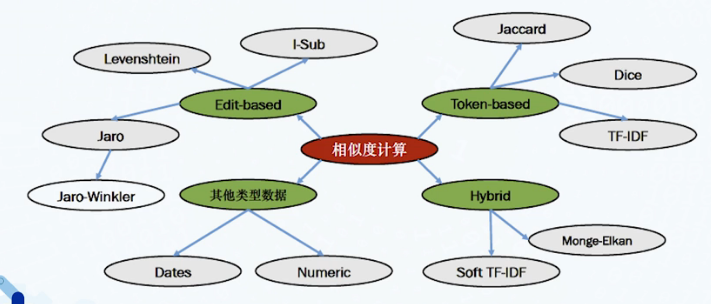
基于语言:依靠自然语言处理技术寻找概念或关系之间的联系
- 内部方法:使用语言的内部属性,如形态和语法特点,寻找同一字符串的不同语言形态
- 外部方法:利用外部的资源,如词典等。使用WordNet能判断两个术语是否有同义或上下义关系
术语匹配的原理
- 核心思想:将文档变为向量的形式,通过向量相似度实现文档匹配
- 本体中的概念和属性往往含有大量的文本信息
- 将待匹配的对象和相关文本组成文档的形式,再转换为文档向量
基于虚拟文档
- 概念的语言学描述:本地名、标签、注释
- 匿名结点的语言学描述:前向邻居的语言学描述
- 概念的邻居:主语邻居、谓语邻居、宾语邻居
- 概念的虚拟文档:自身+邻居结点
结构匹配方法
- 核心思想:利用本体的结构信息来弥补文本信息量不足的情况
- 本体中的概念和属性往往有大量相关的其他概念和属性,组成了一种图结构
- 结构匹配器一般不采用图匹配技术,后者代价高昂且效果不理想
- 间接的结构匹配器
- 在术语匹配器中考虑结构信息,如邻居、上下文、属性等
- 直接的结构匹配器
- 图匹配复杂度高,无法直接使用
- 相似度传播模型的变体很有效
- 间接的结构匹配器
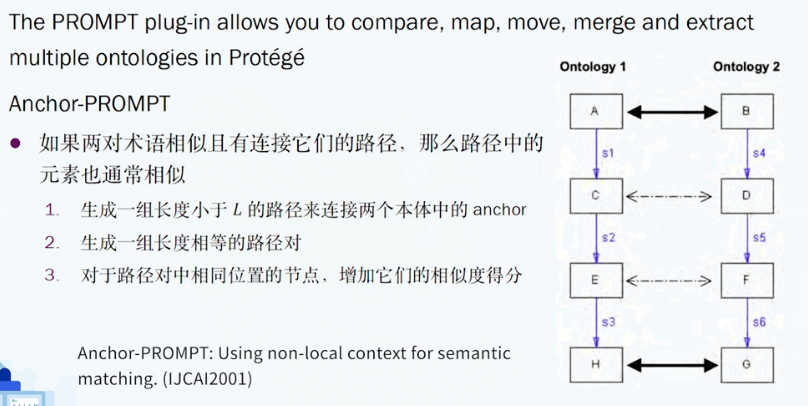
Anchor-PROMPT
大型本体匹配
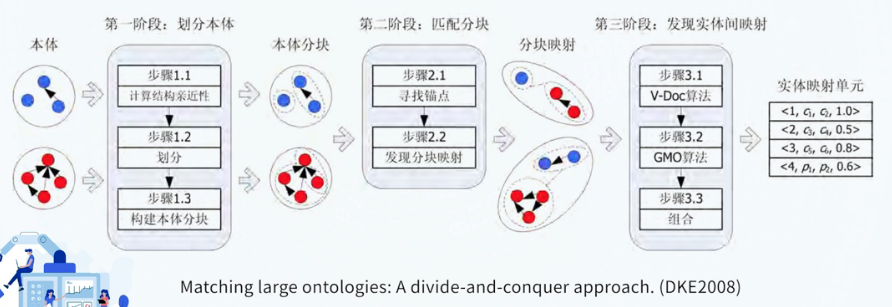
记录进行——链接的时间复杂度为O(|M|*|N|)
分块的方法:
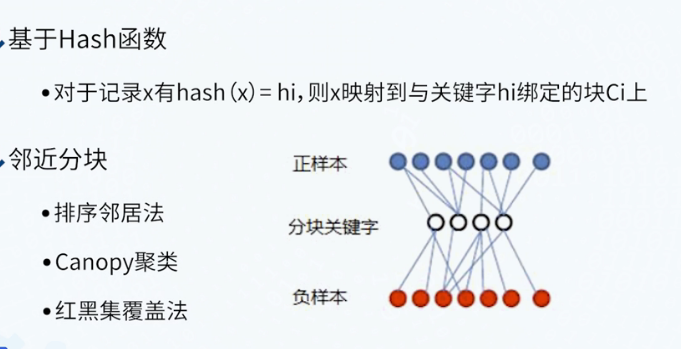
实体对齐(Entity Alignment)
- 发现指称真实世界相同对象的不同实例
- 实体消解、实例匹配
传统方法
- 等价关系推理:OWL等
- 相似度计算
- 计算特征
- 实体标签信息:实体名、昵称、别名
- 人工定义特征:公共邻居、词向量
- 计算相似度:编辑距离、海明距离
- 计算特征
基于表示学习的方法:Embedding- based
一个embedding是一个离散变量到一个连续数字向量的映射
核心思想:基于表示学习技术,将知识图谱中的实体和关系都映射成低维空间向量,直接用数学表达式计算实体间相似度
合并预先匹配好的实体,把两个网络合并为一个网络,用单一网络的嵌入表示进行嵌入

先用单一网络的嵌入模型分别训练两个网络,然后用一些预先匹配好的实体训练一个线性变换对齐两个向量空间
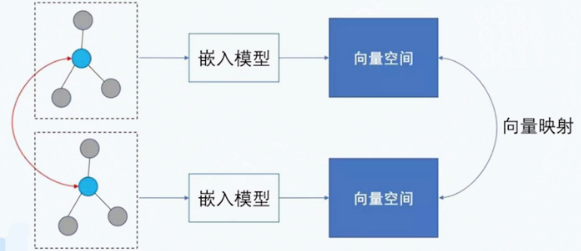

在两个异质知识图谱之间,根据少量种子对齐实体,可以实现大量实体对齐
分别学习两个知识图谱的表示,建立两者映射关系
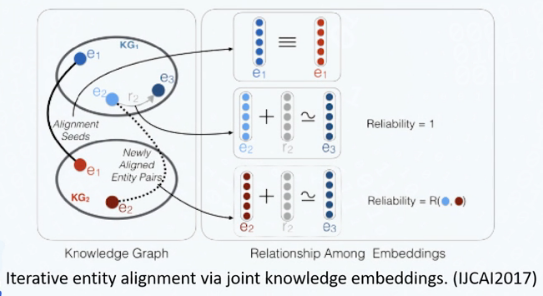
前沿
无监督对齐:不一定都有预先匹配好的实体

多视角嵌入:单一模型的嵌入能力往往不足以对齐两个网络


嵌入表示增强:改进现有的嵌入表示模型并用于对齐
对抗训练:判别器的目标是预测节点的度,生成器的目标是让判别器无法预测节点的度
超大规模对齐:上亿个节点的网络对齐
- 实体异构
- 实体歧义
- 大规模匹配