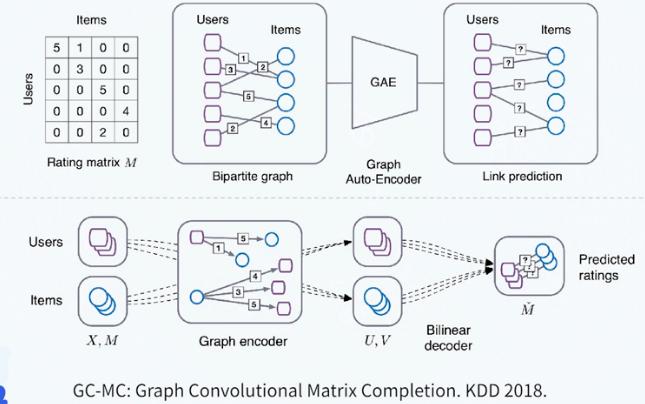
图算法&数据分析
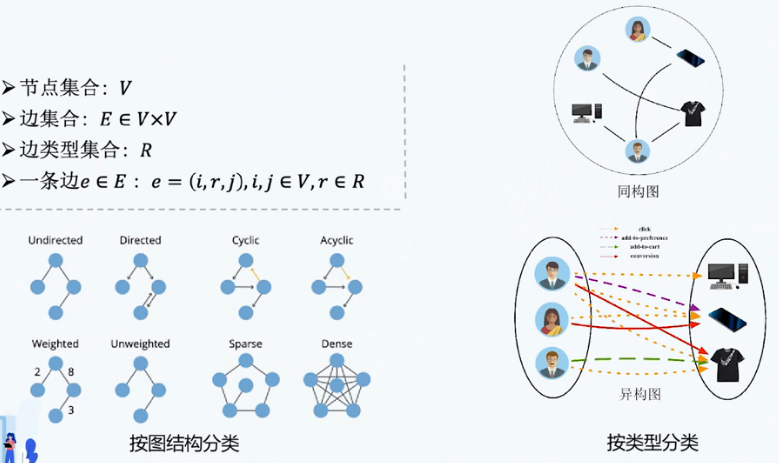
图
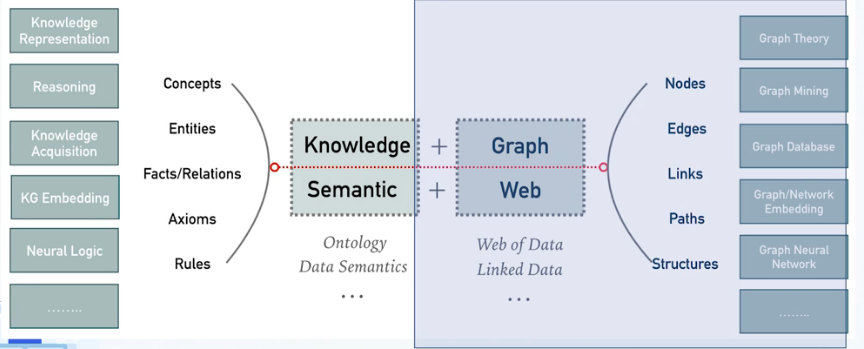
概念
- 节点度
- 入度
- 出度
- 度的分布P(k)=Nk/N
- 邻接矩阵
- 有向图是入度为1
- 二分图
- 最短路径
- 图的直径:图中最长的最短路径
- 平均路径长度:所有节点对的平均最短路径
- 环
- 自回避路径
- 欧拉路径:经过图中所有的边有且只有1次
- 哈密顿路径:经过图中所有的节点有且只有1次
- 聚类系数
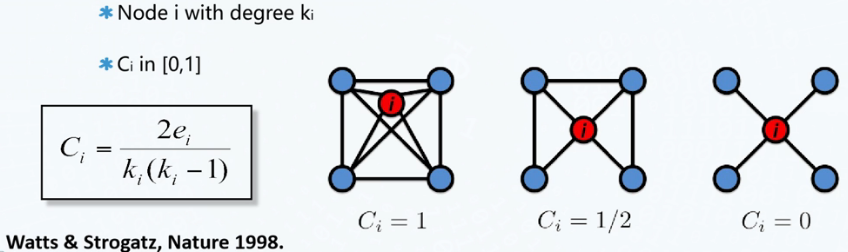
理论
- 六度理论
- 弱联系:
- 如果A与B和C都有联系,那么B和C相互联系的概率大于偶然性,即“朋友的朋友也是我的朋友”。
- 通过弱联系而不是强联系进行信息扩散。
- 无尺度网络:很多复杂系统拥有共同的重要特性:大部分节点只有少数几个连结,而集散节点却拥有与其他节点的大量连结
- Barabasi-Albert模型
- 优先连接:无尺度特性的产生主要来自于网络生成过程中的选择依附,新的节点会优先找已经有很多连接的节点进行连接,类似光环效应
- 幂律分布:P(k)~k^{-γ},2<γ<3
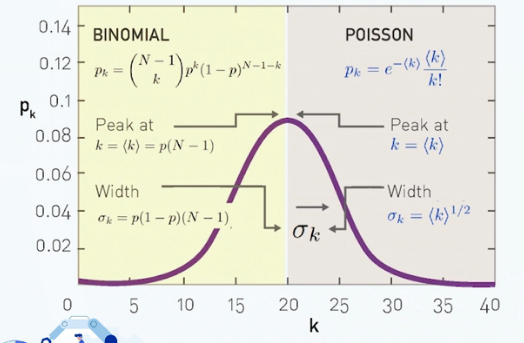
- 随机网络模型:Erdos-Renyi模型
- 构建一个带有n个节点的随机图模型。这个图是通过以概率p独立地在节点(i,j)对之间画边来生成的
- 我们有两个参数:节点数量n和概率p
- 两种分布:二项分布、泊松分布
- 位于k附近的峰值,p越大,网络越稠密
- 宽度由p和k决定,网络越稠密,度分布宽度越高
算法
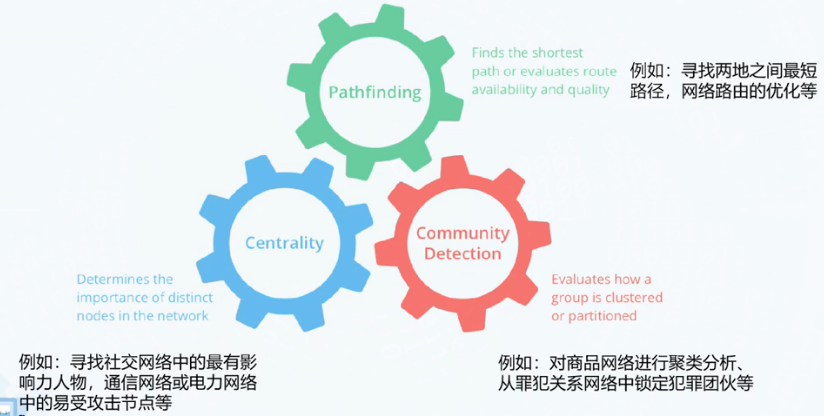
路径搜索
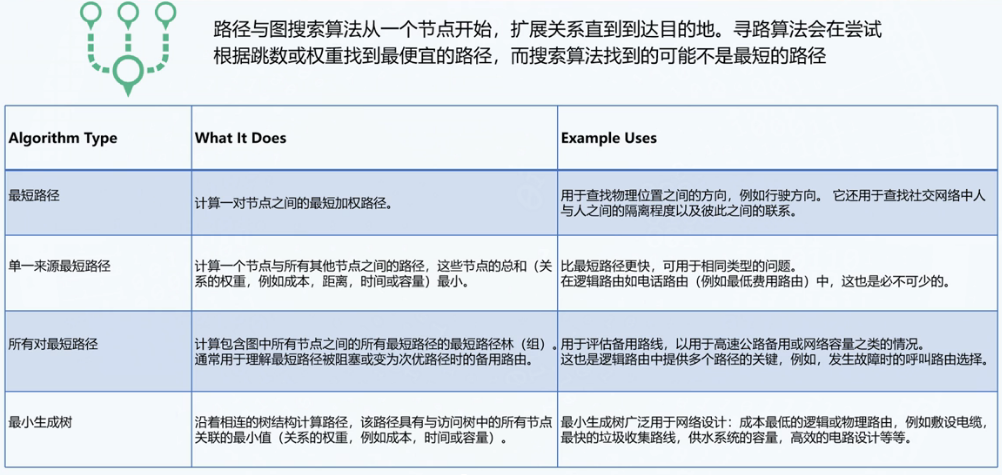
- Dijistra:每次添加离初始点最近的边
- Kruskal:每次添加不在同一棵树的点里最短的边
连通图:在无向图中,若任意两个顶点vi与vj都有路径相通,则称该无向图为连通图
强连通图:在有向图中,若任意两个顶点vi与vj都有路径相通,则称该有向图为强连通图
生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环
最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树
中心度
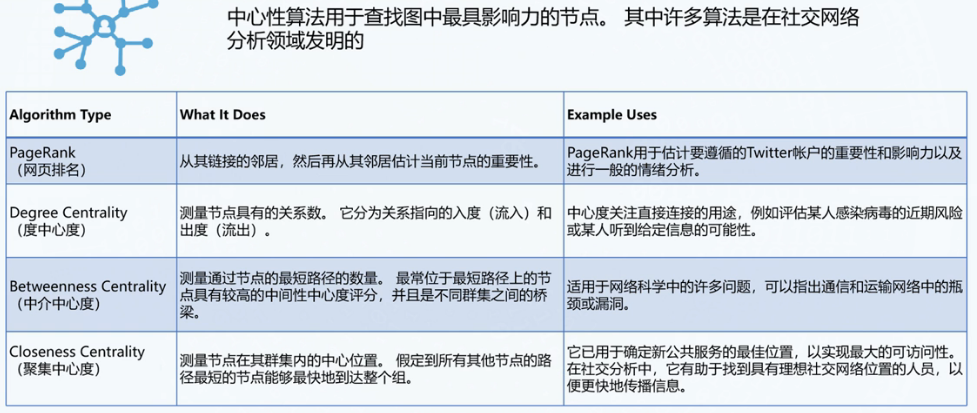
- PageRank:计算到页面链接的数量和质量,从而确定对该页面的重要性的估计。重要页面更有可能收到来自其他有影响力页面的大量链接。
- 计算节点的初始值1/n
- 计算链接值=节点值/出度值
- 计算节点值=∑链接值
- 计算链接值=节点值/出度值
- 迭代1-4
- 中介中间度:检测节点对图形中信息流的影响程度,查找充当从图的一部分到另一部分的桥梁的节点
- 找到所有最短路径
- 对于每个节点,将通过该节点的最短路径数除以图中的最短路径总数,得分越高具有高的中间度
社区发现
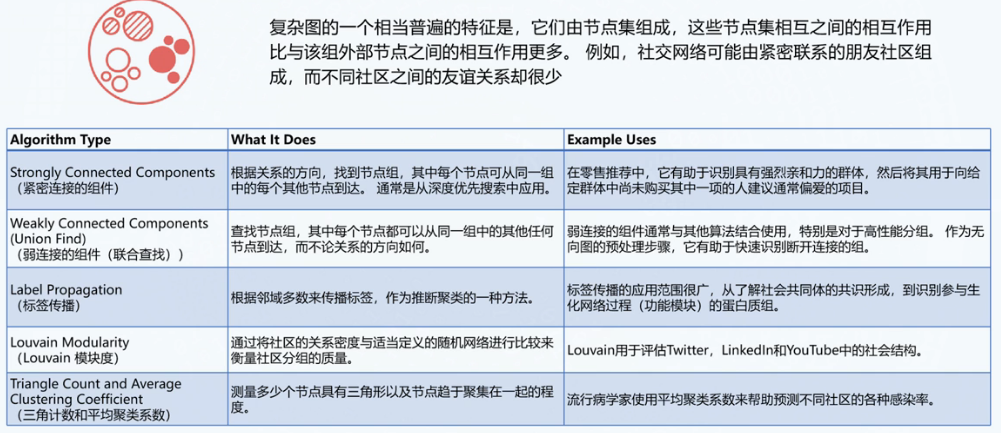
- 查找强连通分量
- Korasaju
- Tarjan
- 标签传播算法:快速发现社区。单个标签可以在密集连接的节点组中迅速占主导地位,但在穿越稀疏连接区域时会遇到麻烦。
- 模块度:衡量社区发现算法结果的质量,刻画发现的社区的紧密程度,被用来当作一个优化函数,即如果能够提升当前社区结构的modularity,则将结点加入它的某个邻居所在的社区中
- m为图中边的总数量
- k_ i表示所有指向节点i的连边权重之和,k_ j同理
- A_ {,j} 表示节点i, j之间的连边权重
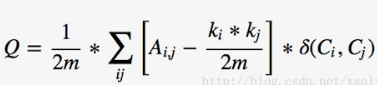
- Louvain算法
- 算法扫描数据中的所有节点,针对每个节点遍历该节点的所有邻居节点,衡量把该节点加入其邻居节点所在的社区所带来的模块度的收益。并选择对应最大收益的邻居节点,加入其所在的社区。这一过程化重复进行直到每一个节点的社区归属都不在发生变化
- 对步骤1中形成的社区进行折叠,把每个社区折叠成一个单点,分别计算这些新生成的“社区点”之间的连边权重,以及社区内的所有点之间的连边权重之和。用于下一轮的步骤1
图表示学习
图表示学习算法:使用深度学习技术在向量空间对图进行表示,同时保留图中的结构特征和语义特征
- 输入:图G= (V,E)
- 输出: V∈R^{|V|×d},d<<|V|,为图中每个节点学一个d维的向量表示v
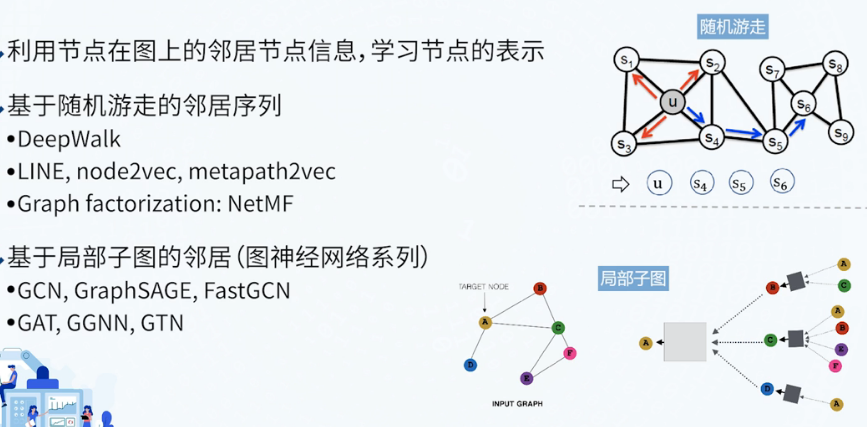
随机游走
DeepWalk
Harris分布式假设
- Word Embedding:处在相似上下文中的词有着相似的语义(e.g.,skip -gram)
- Node Embedding:处在相似结构上下文(structural contexts)中的节点也表达相似的信息
- DeepWalk:结构上下文通过随机游走的路径定义。给定当前节点,预测其周围(同一上下文)节点出现的概率,以无监督的方式训练模型
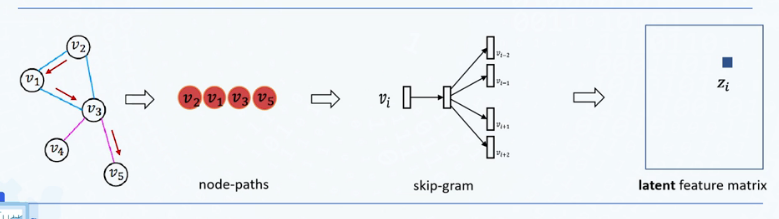
node2vec
内容相似性:相邻的节点是相似的
结构相似性:具有相似子图结构的节点也是相似的(但结构上相似的节点并不一定相邻)
Node2vec:尽可能地捕捉/利用节点的相似性信息
- BFS:采样内容上相似的节点
- DFS:采样结构上相似的节点

LINE
通过节点间的一阶近似和二阶近似建模邻居节点信息
- 一阶近似:两个节点之间相连的边权重越大,两节点越相似
- 二阶近似:两个节点之间共享的邻居越多,两节点越相似
适用于:大规模图谱,以及有向图、无向图、有权重图、无权重图等边类型复杂的图谱
NetMF

Metapath2vec
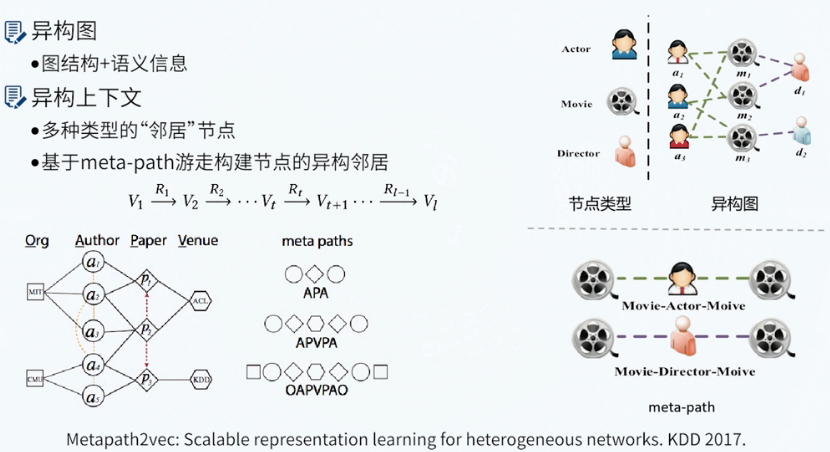
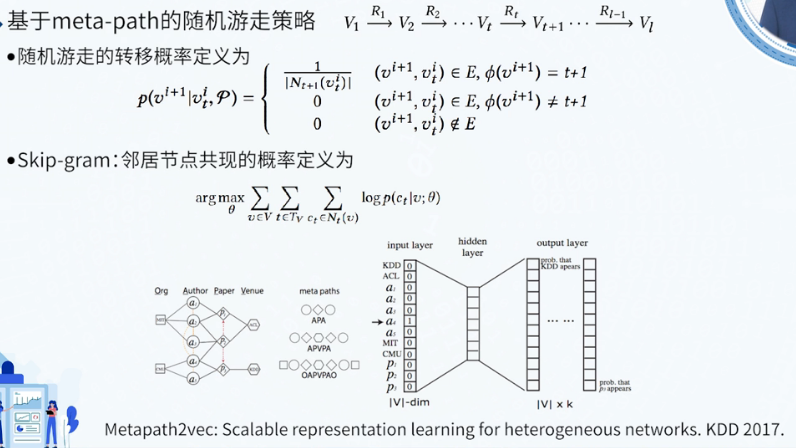
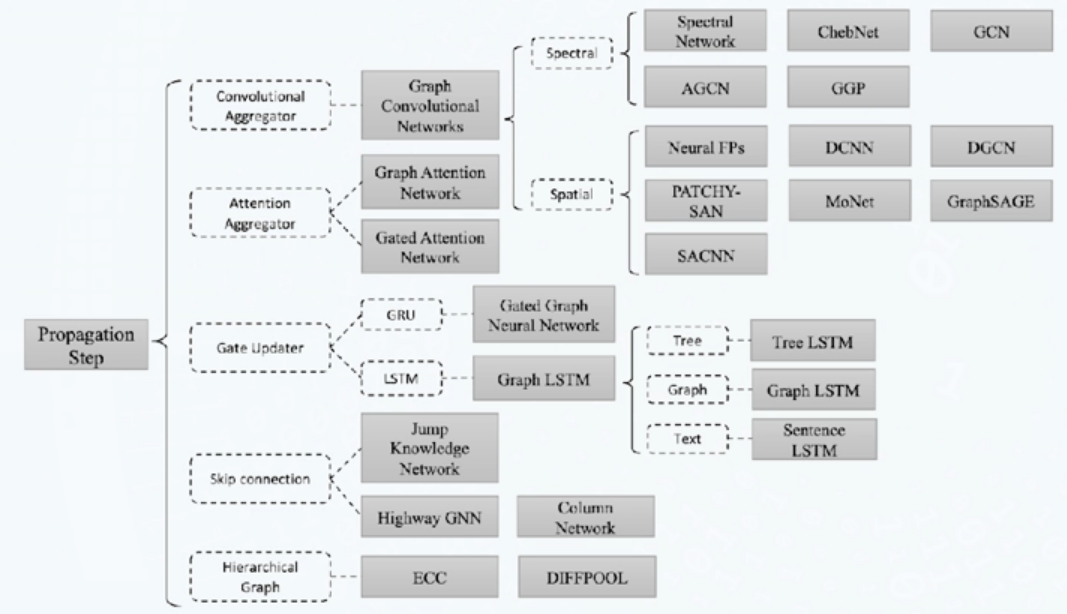
图神经网络
- 信息传播模块:聚合周围邻居节点的信息,在节点间进行信息传播并以此更新节点的隐藏层状态
- 聚合器:使用神经网络模块聚合周围节点信息/特征
- 迭代器:基于当前节点的表示和周围节点的特征更新周围节点的表示
- 输出模块:基于学习到的节点表示,根据任务定义目标函数
Transductive Setting:图中的部分未标注数据同时也是测试数据
图卷积神经网络(Graph Convolutional Network, GCN)
基本聚合函数的简单变种:节点自身及其周围节点共享参数矩阵
不同于聚合时直接求取平均值,对每个邻居节点的表示进行正则化
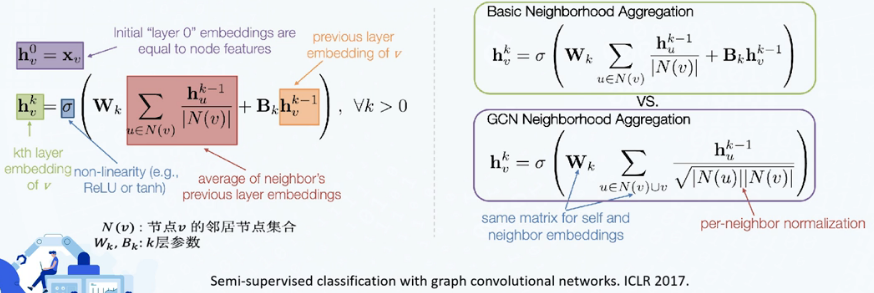
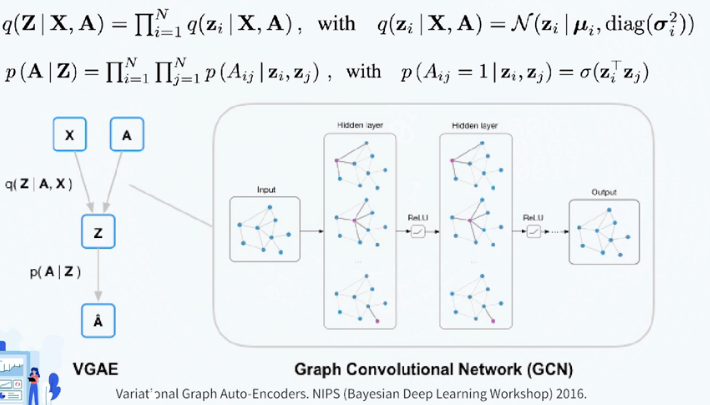
图变分自编码器(Variational Graph Autoencoder, VGAE)
门控图神经网络(Gated graph sequence neural networks, GGNN)
带权重的聚合操作:为某个节点的邻居节点学习不同的权重
每个“节点-邻居节点对”之间是并行计算的,因此操作十分高效
模型可泛化到新图谱上
Inductive Setting:新的、训练时未见过的节点/子图等上测试的话
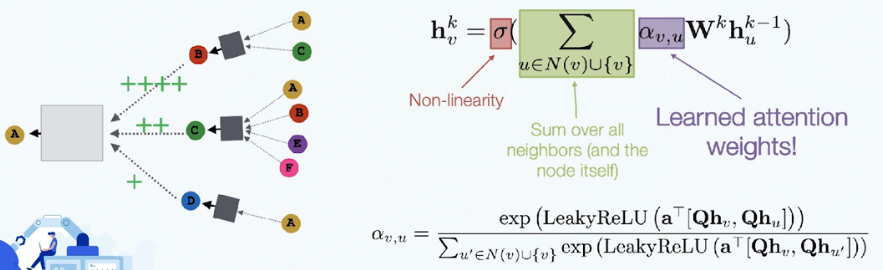
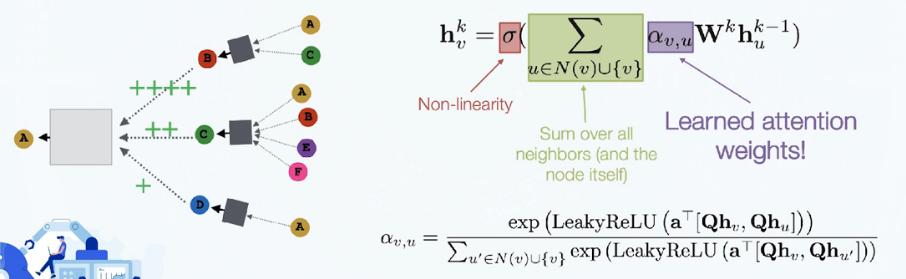
图注意力神经网络(Graph Attention Network, GAT)
带权重的聚合操作:为某个节点的邻居节点学习不同的权重
每个“节点-邻居节点对”之间是并行计算的,因此操作十分高效
模型可泛化到新图谱上
GraphSAGE
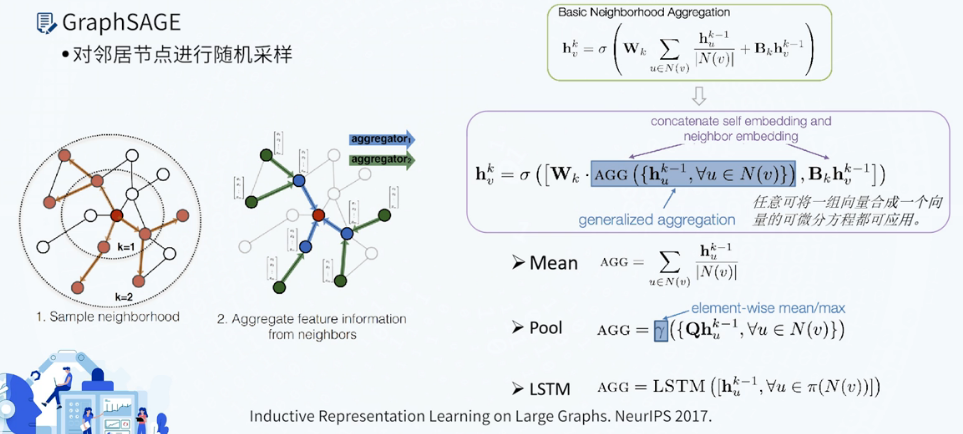
模型的参数量与节点数量|V|线性相关,并且可泛化到新的节点
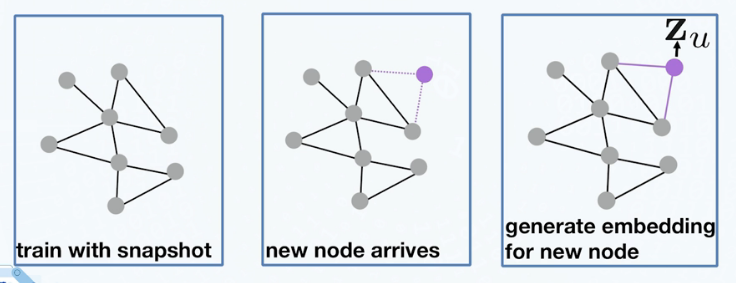
Graph Transformer Network(GTN)
处理如知识图谱等异构图,通过一维卷积选择某些关系对应的邻接矩阵,并生成新的连接关系(meta path)
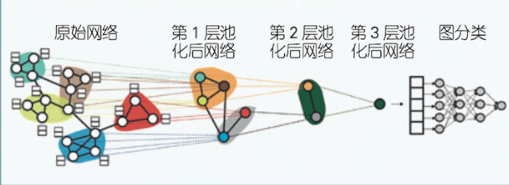
层次化模型
- 有一些图级别的挖掘任务需要对图的不同粒度层次的信息进行建模,有研究者提出层次化的图神经网络模型。
- 关键的是图的粗化过程,即不断将相似节点聚类在一起,形成一个新的超节点
- 超节点的表示由聚类一起的相似节点共同作用得到,超节点之间的连接边由聚类分配矩阵和原邻接矩阵共同作用得到。
- 典型的模型如Diffpool等
预训练
图网络的标签数据通常很难获取
设计自监督学习任务,从无标签数据中预训练图神经网络模型
现有工作
- 基于生成模型的预训练图神经网络
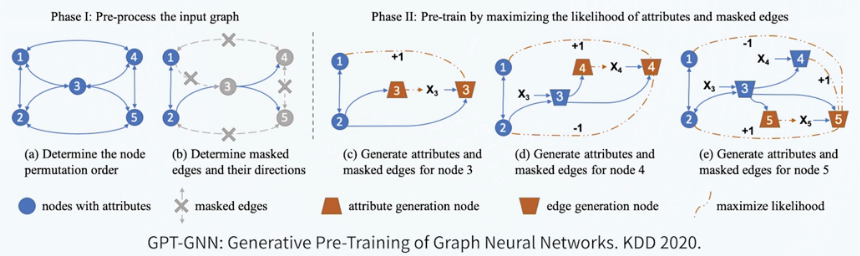
GPT-GNN
预训练任务:将输入图数据的生成概率最大化,包括图的结构生成和属性生成
预训练过程:
- 对输入图谱中所有节点随机预定义一个顺序;
- 随机遮盖序列中的节点连边和属性;
- 自回归地生成被遮盖的节点连边及属性;
- 在下一次迭代过程中,采用不同的节点顺序继续进行自回归式的生成建模
在同一数据的不同下游任务上分别进行微调(仅用10%- 20%的标记数据)
Pre-training GNNs on chemistry and biology Graph
- 基于对比学习的预训练图神经网络
DGI
InfoGraph
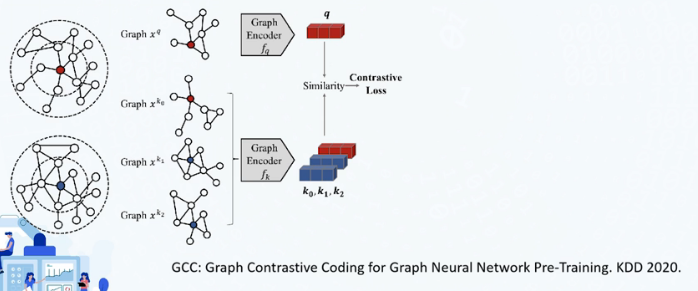
GCC
从无标注多领域输入图数据中构造正负例进行对比学习的图神经网络预训练框架
对输入的多领域图数据构造正负子图
使用对比学习方法如InfoNCE等进行子图判别任务
多领域数据图的预训练,可很好地泛化到不同领域的下游任务上
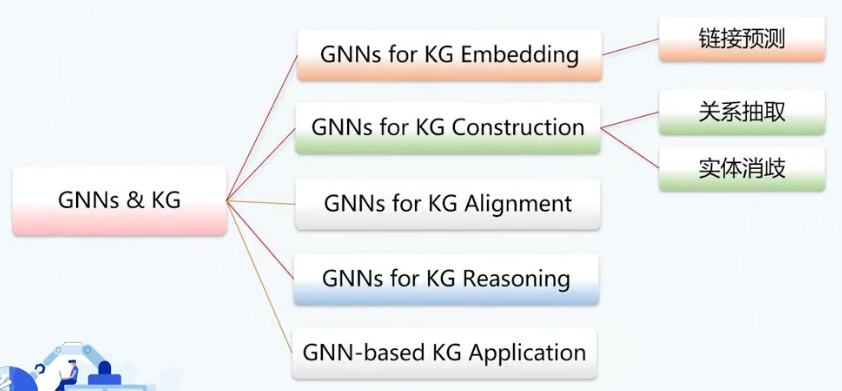
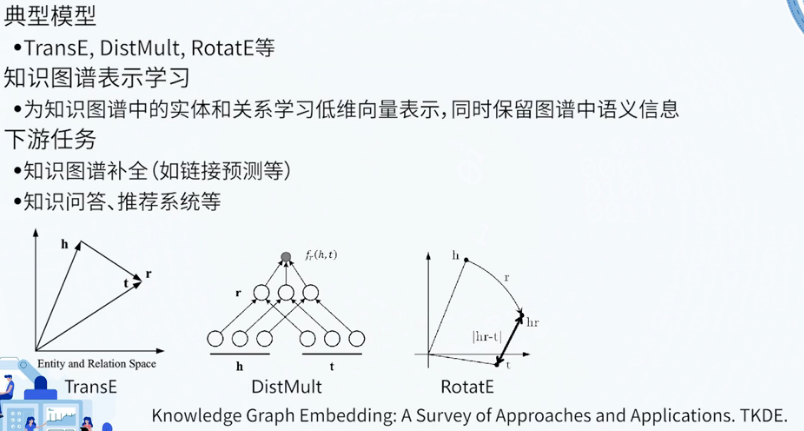
图神经网络 & 知识图谱表示学习
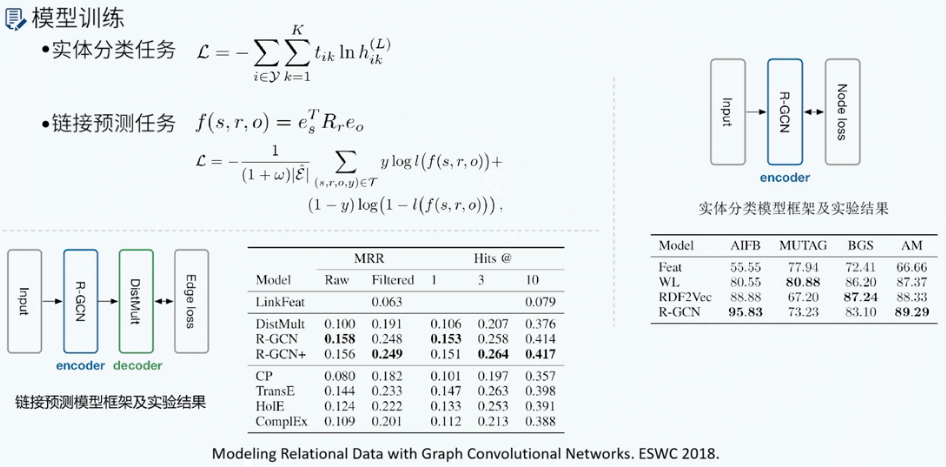
RGCN

COMPGCN
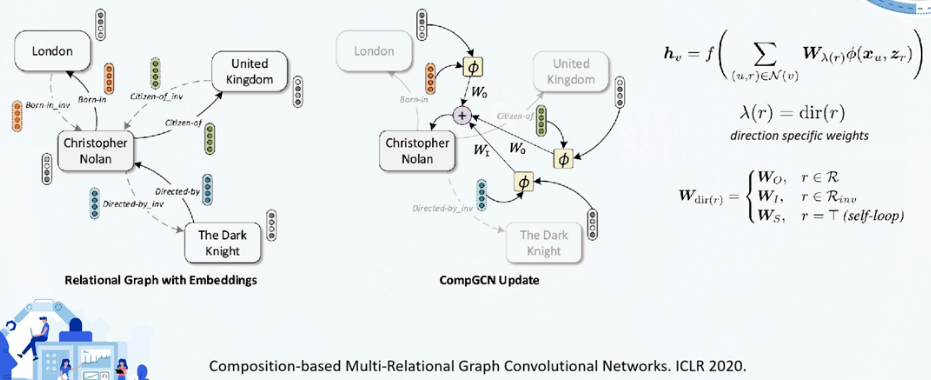
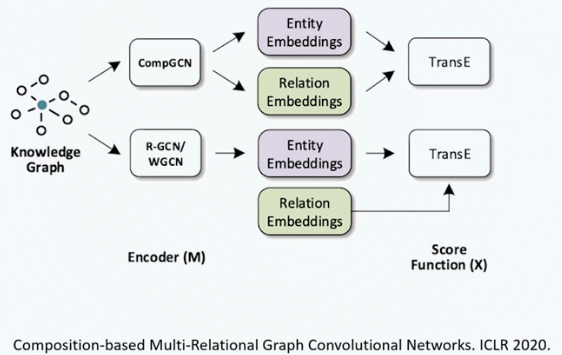
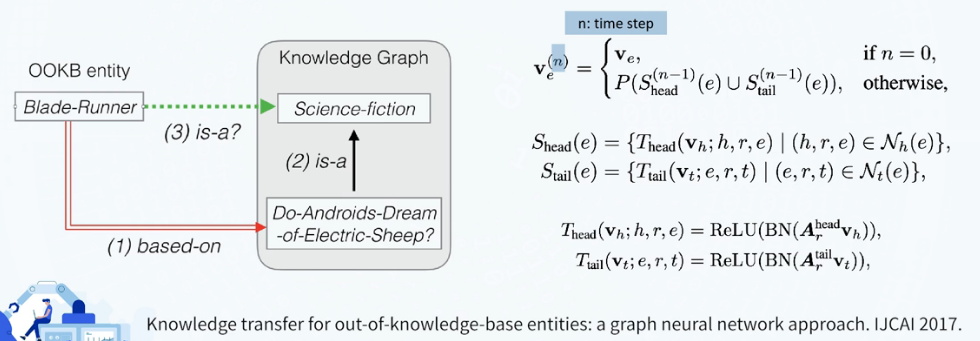
Inducitvie
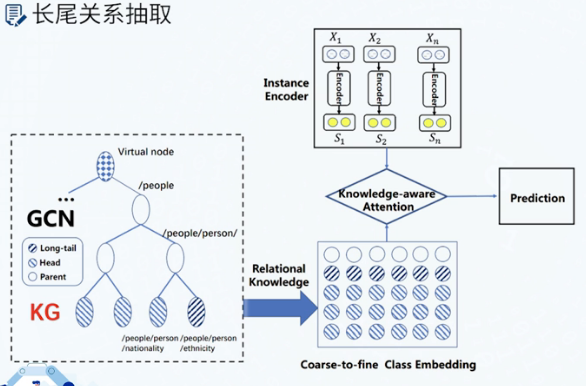
长尾关系抽取
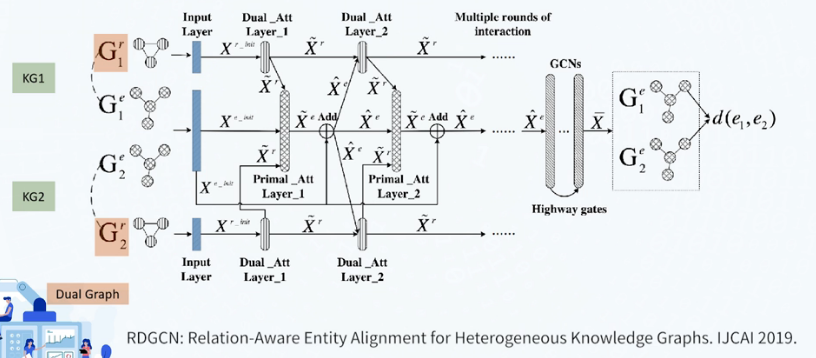
知识图谱对齐
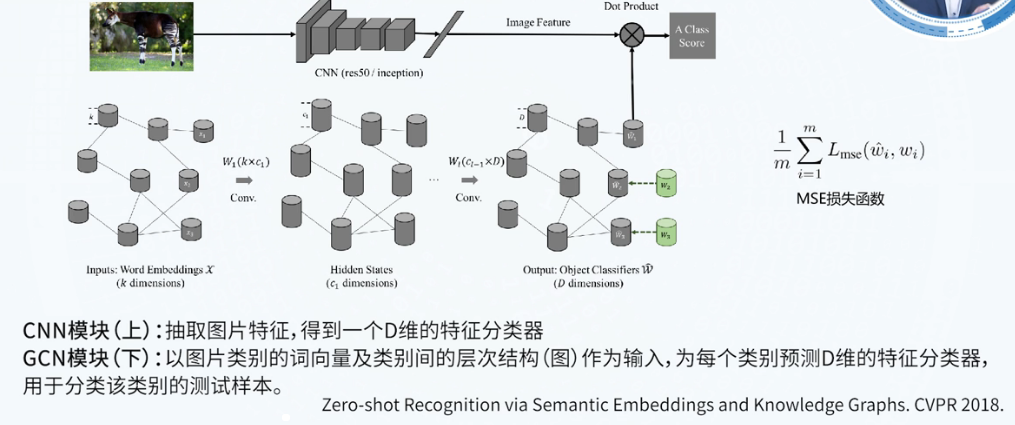
零样本图像分类
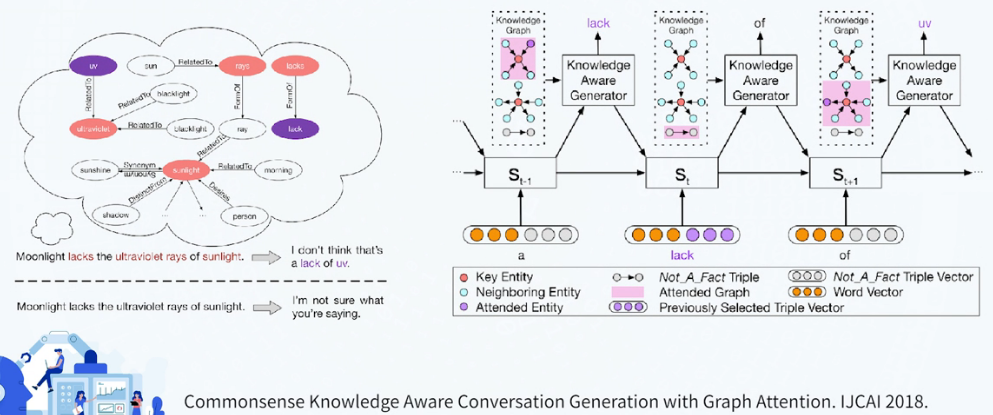
文本生成
推荐系统