SVM支持向量机
支持向量机(Support vector machine, SVM)解释
1.支持向量(support vector):支持或支撑平面上把两类类别划分开来的超平面的向量点。
2.“机”(机器,machine):“机”实质上是一个算法。在机器学习领域,常把一些算法看做是一个机器,如分类机(当然,也叫做分类器)
支持向量机基本模型是在特征空间上找到最佳的分离超平面使得训练集上正负样本间隔最大。SVM是用来解决二分类问题的有监督学习算法(实际上还有多分类),在引入了核方法之后SVM也可以用来解决非线性问题
SVM 基本概念
将实例的特征向量(以二维为例)映射为空间中的一些点,如下图的实心点和空心点,它们属于不同的两类。SVM 的目的就是想要画出一条线,以“最好地”区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。

Q1:能够画出多少条线对样本点进行区分?
答:线是有无数条可以画的,区别就在于效果好不好,每条线都可以叫做一个划分超平面。比如上面的绿线就不好,蓝线还凑合,红线看起来就比较好。我们所希望找到的这条效果最好的线就是具有 “最大间隔的划分超平面”。
Q2:为什么要叫作“超平面”呢?
答:因为样本的特征很可能是高维的,此时样本空间的划分就不是一条线了。
Q3:画线的标准是什么?/ 什么才叫这条线的效果好?/ 哪里好?
答:SVM 将会寻找可以区分两个类别并且能使间隔(margin)最大的划分超平面。比较好的划分超平面,样本局部扰动时对它的影响最小、产生的分类结果最鲁棒、对未见示例的泛化能力最强。
Q4:间隔(margin)是什么?
答:对于任意一个超平面,其两侧数据点都距离它有一个最小距离(垂直距离),这两个最小距离的和就是间隔。比如下图中两条虚线构成的带状区域就是 margin,虚线是由距离中央实线最近的两个点所确定出来的(也就是由支持向量决定)。但此时 margin 比较小,如果用第二种方式画,margin 明显变大也更接近我们的目标。

Q5:为什么要让 margin 尽量大?
答:因为大 margin 犯错的几率比较小,也就是更鲁棒啦。
Q6:支持向量是什么?
答:从上图可以看出,虚线上的点到划分超平面的距离都是一样的,实际上只有这几个点共同确定了超平面的位置,因此被称作 “支持向量(support vectors)”,“支持向量机” 也是由此来的。
SVM有三宝:
间隔 用于建模

间隔最大化转化为数学表示:
目标:

条件:

最终优化为:

对偶 用于模型求解
最优:

核技巧 将非线性问题转化为线性问题
SVM的三个重要的算法
硬间隔:hard-margin SVM
当训练数据线性可分时,可通过硬间隔最大化学得一个线性可分支持向量机。
软间隔:soft-margin SVM
当训练数据近似线性可分时,可通过软间隔最大化学得一个线性支持向量机。
核方法:kernel SVM
当训练数据线性不可分时,可通过核方法以及软间隔最大化学得一个非线性支持向量机。
相关概念补充
线性可区分和线性不可区分
能够用一条直线对样本点进行分类的属于线性可区分(linear separable),否则为线性不可区分(linear inseparable)。

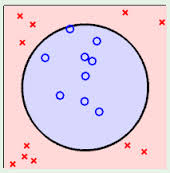

以下三个例子,都是线性不可区分的,即无法用一条直线将两类样本点区分开。
而刚才的例子就是线性可区分的。
在线性不可分的情况下,数据集在空间中对应的向量无法被一个超平面区分开,如何处理?
:两个步骤来解决:
1.利用一个非线性的映射把原数据集中的向量点转化到一个更高维度的空间中(比如下图将二维空间中的点映射到三维空间)
2.在这个高维度的空间中找一个线性的超平面来根据线性可分的情况处理

比如想要将红点和蓝点变成线性可分的,那么就将映射 y = x,变成映射 y = x^2,这样就线性可分了。

视觉化演示:https://www.youtube.com/watch?v=3liCbRZPrZA
SVM 可扩展到多分类问题
SVM 扩展可解决多个类别分类问题:
对于每个类,有一个当前类和其他类的二类分类器(one-vs-rest)
将多分类问题转化为 n 个二分类问题,n 就是类别个数。
SVM 算法特性
1,训练好的模型的算法复杂度是由支持向量的个数决定的,而不是由数据的维度决定的。所以SVM 不太容易产生 overfitting。
2,SVM 训练出来的模型完全依赖于支持向量,即使训练集里面所有非支持向量的点都被去除,重复训练过程,结果仍然会得到完全一样的模型。
3,一个 SVM 如果训练得出的支持向量个数比较少,那么SVM 训练出的模型比较容易被泛化。