大促过程问题汇总
问题一、通过监控、分析过去7天各系统慢SQL统计情况,发现10.27.150.50服务器在6月1日的慢SQL数量

查看50上的慢SQL统计
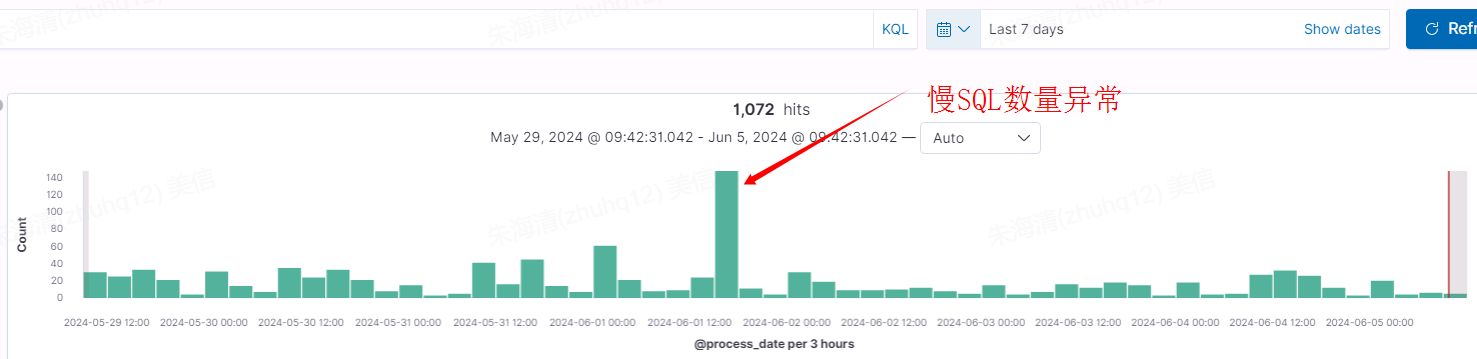
逐渐缩小范围
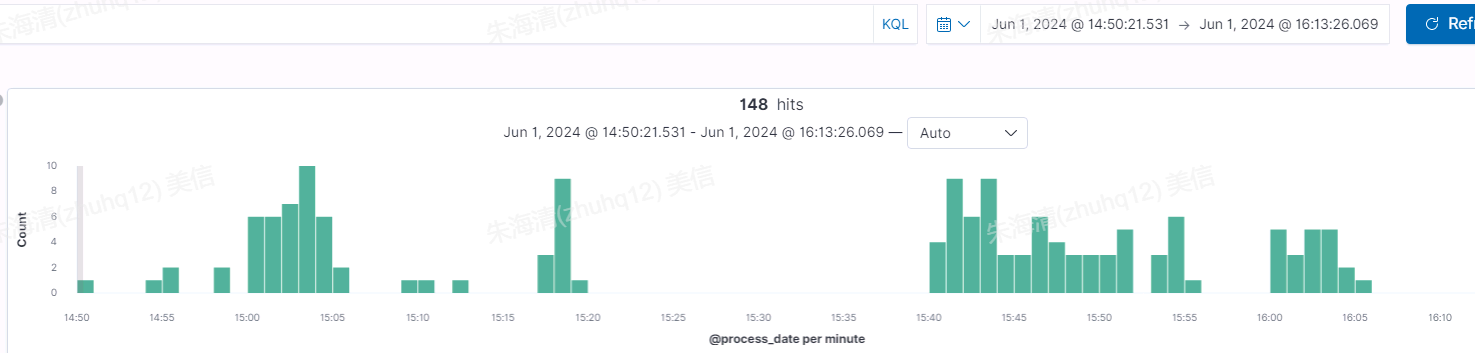
查看具体的慢SQL
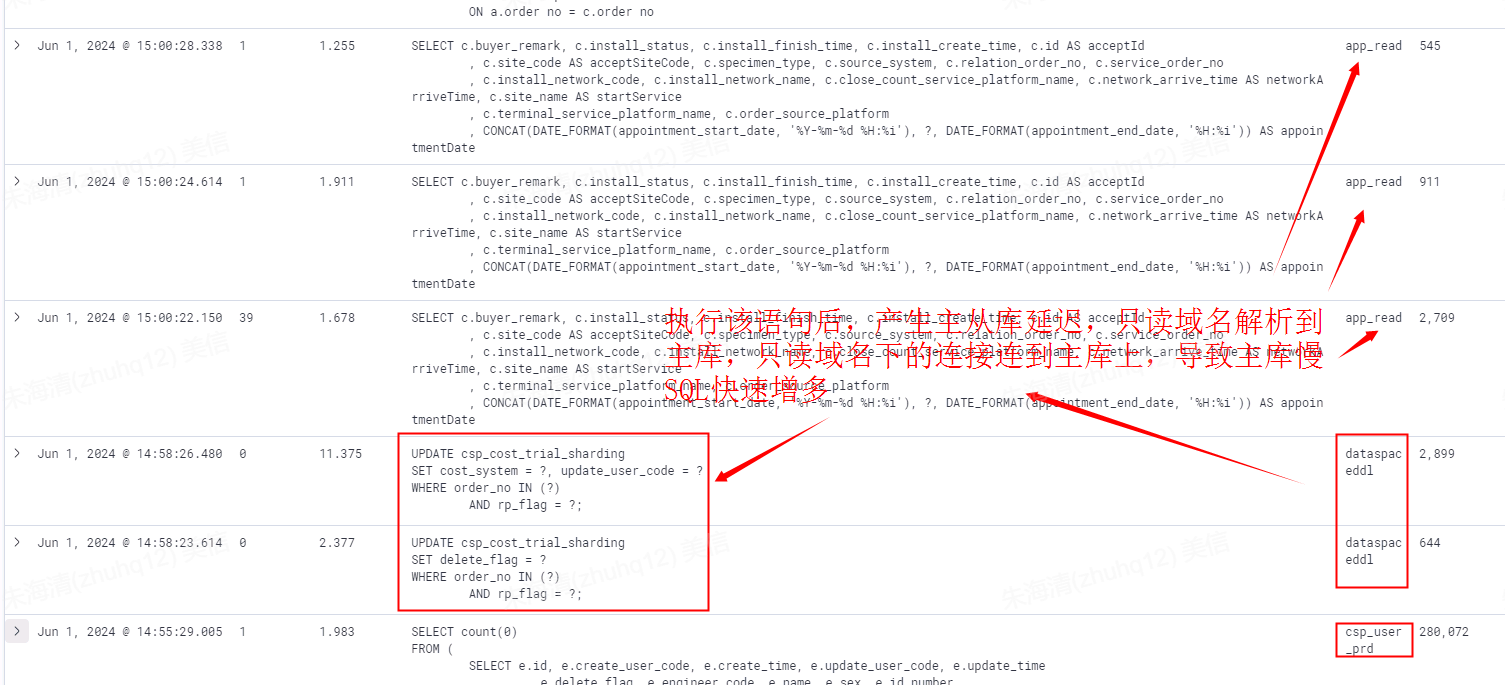
找到 dataspaceddl 执行以上2条update语句之后,就会造成主从同步的延迟,此时只读域名解析会解析得到主库IP,app_read只读连接连到主库50上,导致主库上的慢SQL快速增多。经过分析定位,发现 dataspaceddl 执行的2条SQL都是运维提交的修数脚本。
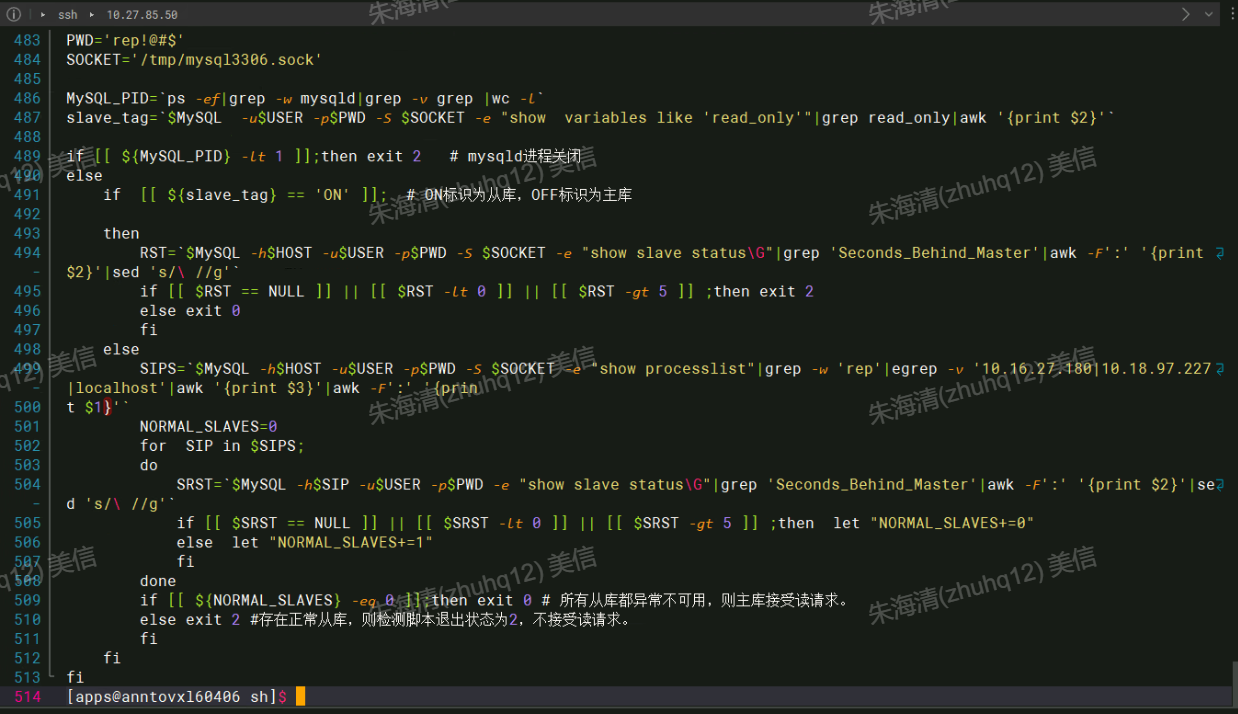
以上是DBA维护的域名解析shell脚本,可以看出主从延迟超过5秒就会解析到主库上面。
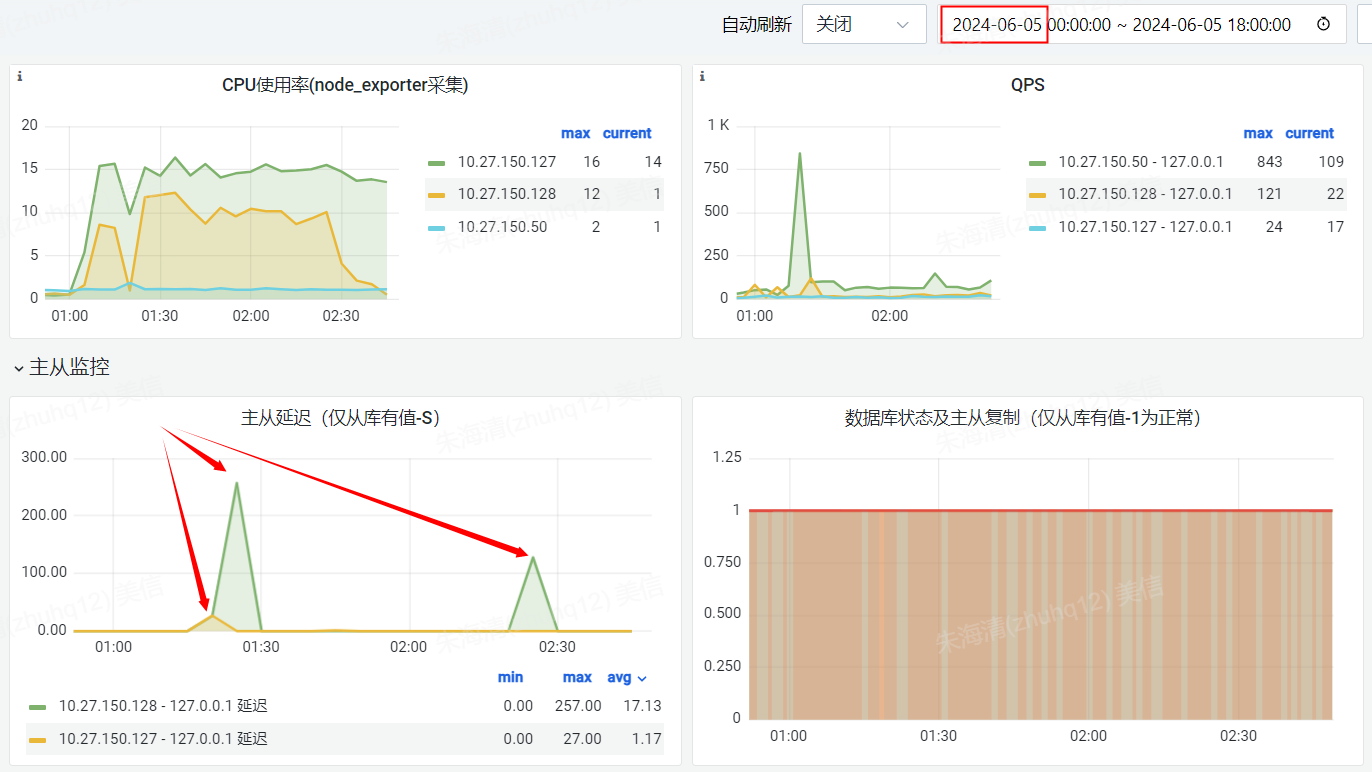
问题二、通过监控、分析C-CSP每天的主从延迟,发现1:25和2:25都有产生主从延迟
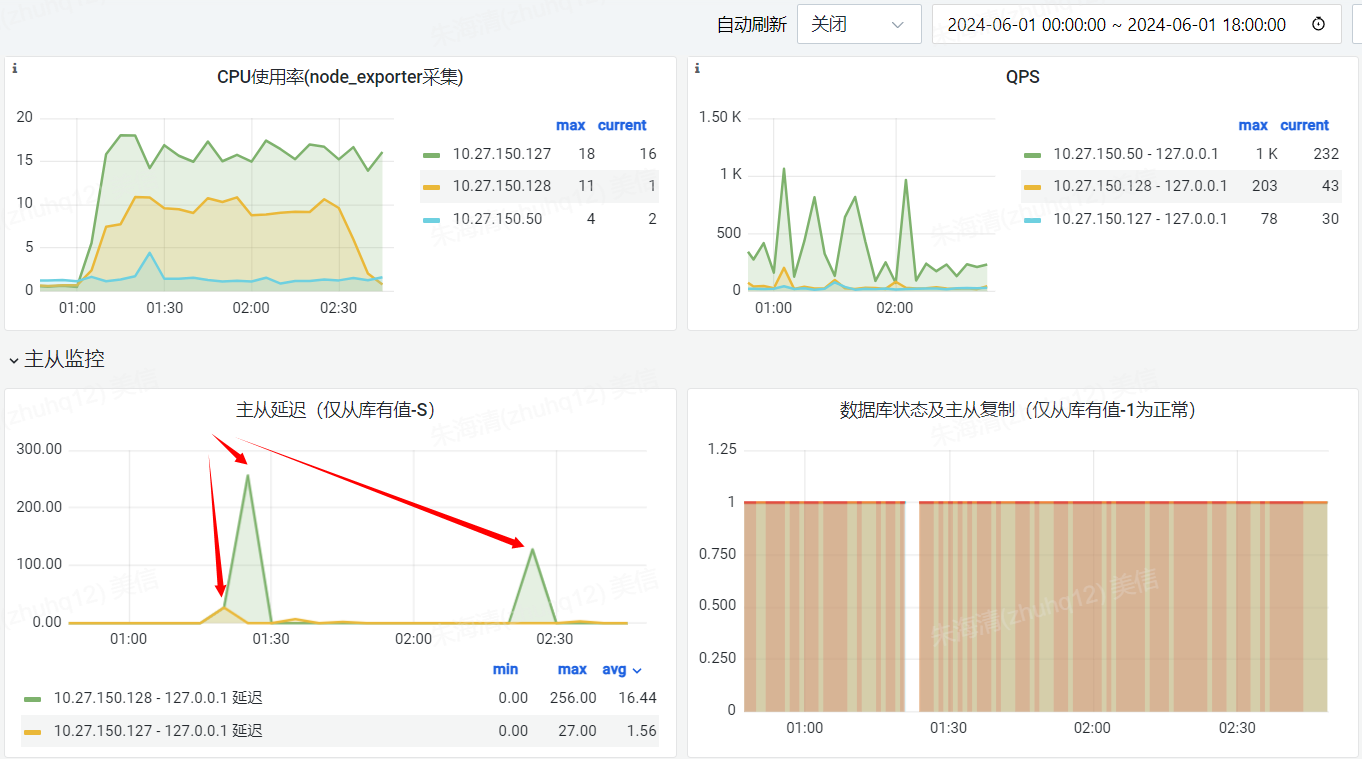
6月5日
分析这个时间段的API接口调用情况
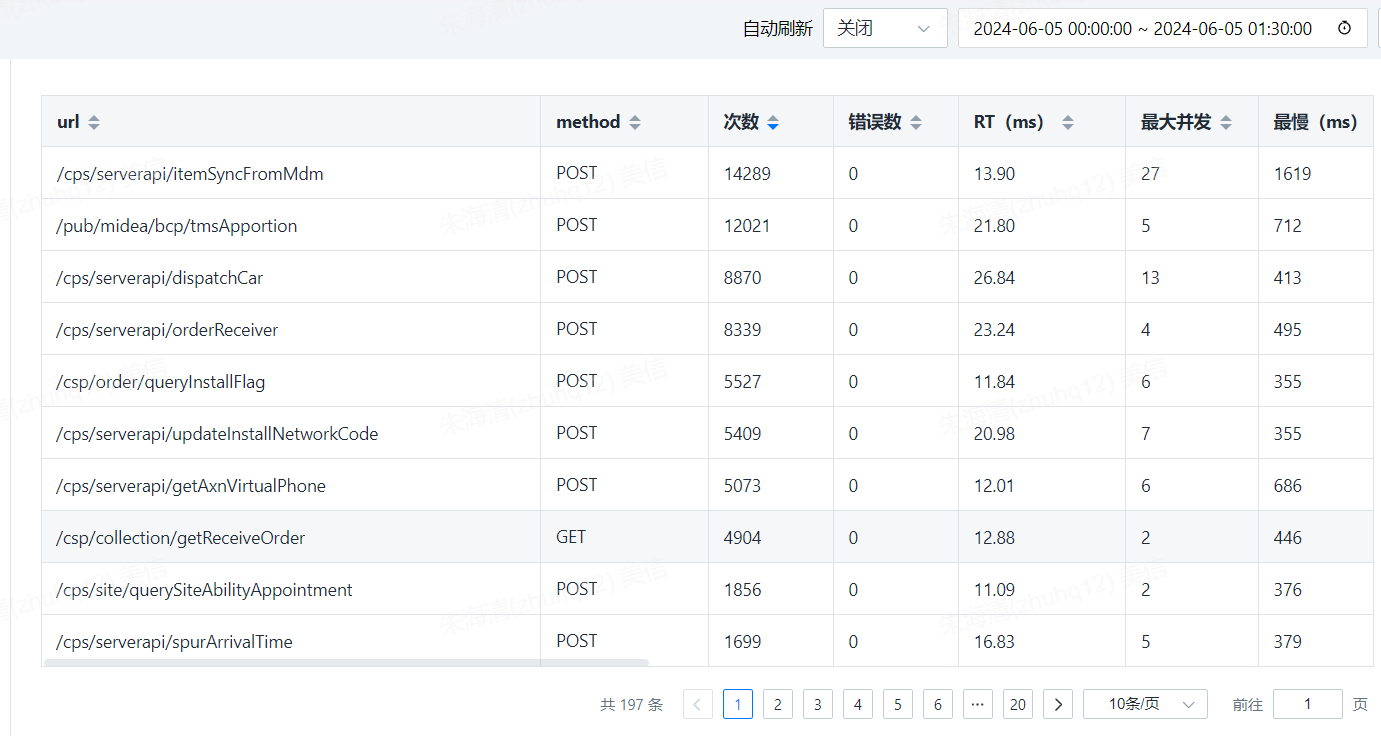
具体商品信息同步接口调用走势为例
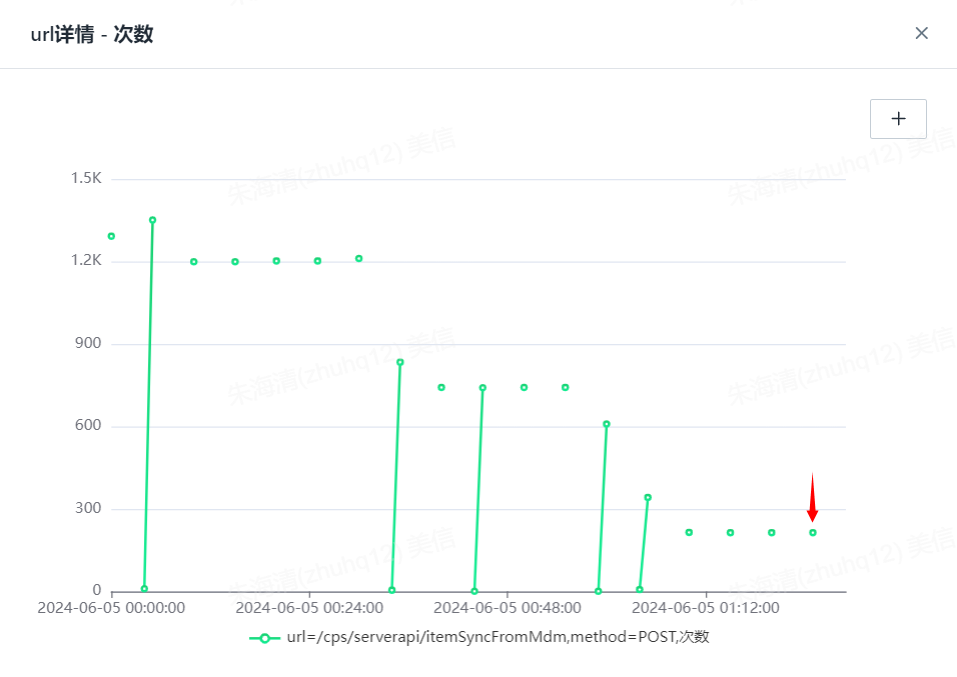
这个时间点也不是商品同步接口调用最多的时刻,这个时间点的主从延迟应该和这个接口没关系。
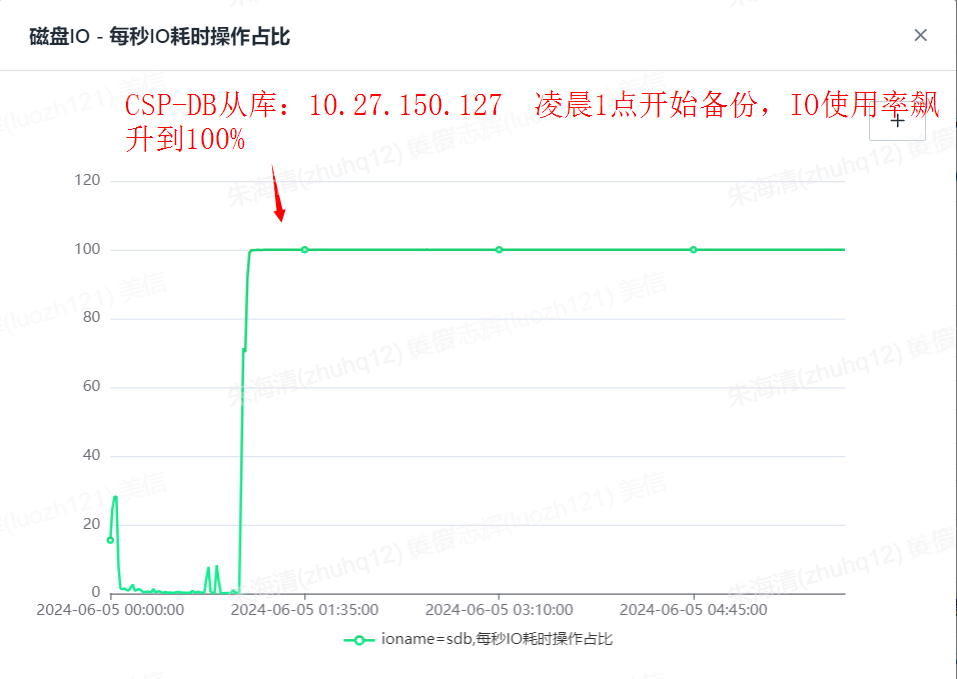
从库127备份
从库128备份
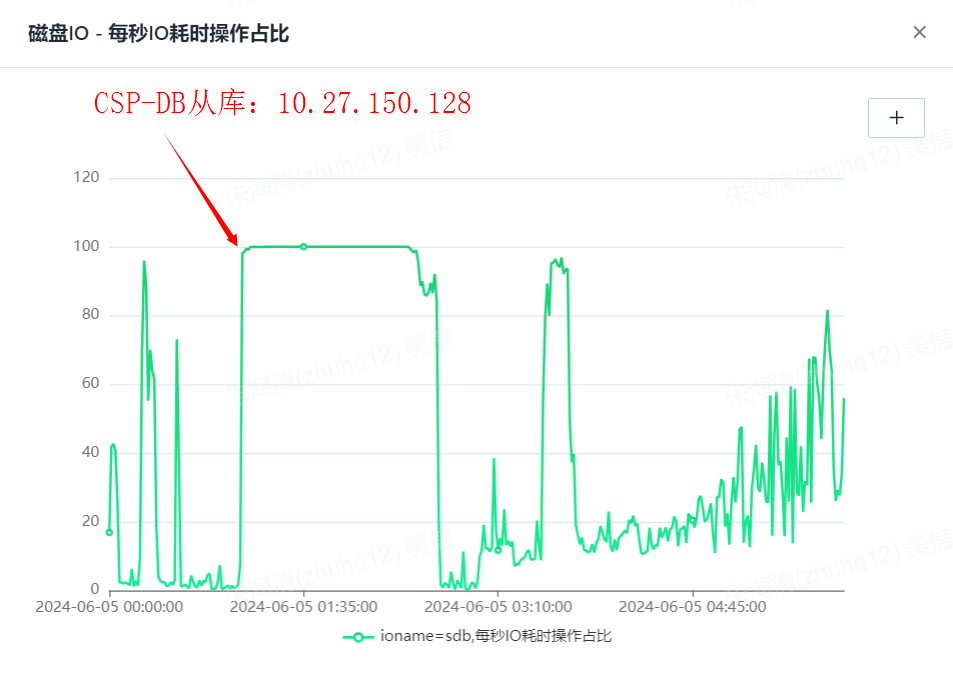
分析主机的IO情况,由上面IO监控截图可以看出,2台从库都从1点多开始备份(IO被打满,影响从库上事务回放,导致产生主从延时),2点多的是计费异常处理。
由此,可以确定C-CSP的DB服务以上2个时间点的主从延迟原因,都是因为数据库备份引起的IO打满,导致DB事务回放延时。
问题三、发现C-CSP系统容器云节点从6月8日开始出现内存告警
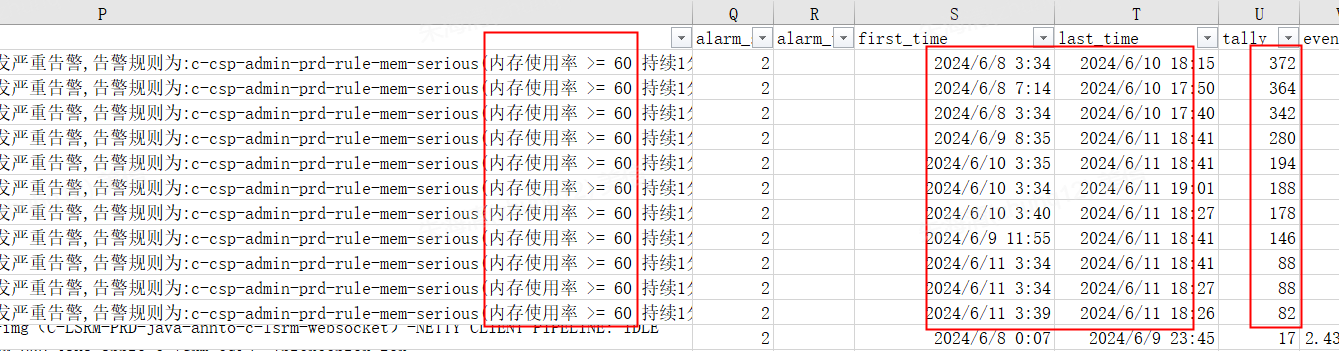
C-CSP系统由于618大促封板,之前最后一个版本为5月24日,6月8日开始个别容器节点出现内存告警。
发现一个规律,CSP系统启动时间越久,越到后面越容器产生内存告警。
节点启动2天时,内存使用率最多是56%,当前logs目录为150M~200M;一周之后达到500M~700M,已有部分节点触发内存使用率超过60%的告警。时间越久这个logs目录文件越大,内存告警的频率也就越高。
下次大促,记得调整一下日志策略,保留3天。