python网络爬虫
unicode到其他编码:encode
其他编码到unicode:decode
Python访问互联网
URL:网页地址, 统一资源定位符 , 对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。
lib:library
URL + lib == urllib(包)
URL的一般格式,[可选项]
protocol://hostname[:port]/path/[;parameters][?query]#fragment
组成:
第一部分(协议):http, https, ftp, file, ed2k……
第二部分:存放资源的服务器或域名系统或IP[端口号]
第三部分:资源的具体地址,如目录或文件名
urllib包:
urllib.request 打开和读取URL的请求
urllib.error 包含urllib.request引发的异常
urllib.parse 用于解析URL
urllib.robotparser 用于解析robots.txt文件
from urllib import request
url = 'https://www.baidu.com'
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36"
}
#User-Agent: 普通浏览器会通过该内容向访问网站提供你所使用的浏览器类型、操作系统、浏览器内核等信息的标识
req = request.Request(url,headers=head)
response = request.urlopen(req)
html = response.read().decode('utf-8')
print(html)
request.urlopen()#对于HTTP和HTTPS URLs,此函数返回HTTP://client.HTTPResponse,需要用read(读取的字节数)方法读出内容
URI:统一资源标识符
用一句话概括它们的区别:URI 是用字符串来标识某一互联网资源,而 URL 则是表示资源的地址(我们说某个网站的网址就是 URL),因此 URI 属于父类,而 URL 属于 URI 的子类。
import urllib.request
import urllib.parse
import chardet
import json
content = input("输入要翻译的内容:")
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data = {}
data['i'] = content
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = '15860732825741'
data['sign'] = '64a222dc77968fbf373b4eecac7e6bb2'
data['ts'] = '1586073282574'
data['bv'] = '70244e0061db49a9ee62d341c5fed82a'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_REALTlME'
data = urllib.parse.urlencode(data).encode('utf-8')
head = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"}
req = urllib.request.Request(url, data = data, headers = head)
#当data不是默认值时(也没有赋值为Null),将会进行POST:向服务器发送数据,否则将会进行GET:向服务器请求数据
#可以通过Request生成之后通过Request.add_header()将headers添加进去
response = urllib.request.urlopen(req)
html = response.read()
html = html.decode('utf-8')
target = json.loads(html)
print("翻译结果 : %s" % (target['translateResult'][0][0]['tgt']))
伪装爬虫:
- 减慢爬虫的速度
代理:
代理ip:百度即可
1. 设置一个字典{'类型' : '代理IP : 端口号'}
proxy_support = urllib.request.ProxyHandler({})
2. 定制、创建一个opener
opener = urllib.request.build_opener(proxy_support)
#是否添加headers
opener.addheaders = [('User-Agent', '')]
3a. 安装opener
urllib.request.install_opener(opener)#将默认open改成定制好的opener
之后就可以使用正常的访问形式了
3b. 调用opener
opener.open(url)#暂时使用特殊的opener
#urlopen()使用的是默认的opener
异常处理:
URLError
try:
urllib.request.urlopen(req)
except urllib.error as e:
print(e.reason)
HTTPError是URLError的子类,需要写在URLError前
try:
urllib.request.urlopen(req)
except urllib.error.HTTPError as e:
print(e.code)
print(e.read())
其他写法
try:
urllib.request.urlopen(req)
except URLError as e:
if hasattr(e, 'reason'):
print('Reason:', e.reason)
elif hasattr(e, 'code'):
print('Error code:', e.code)
else:
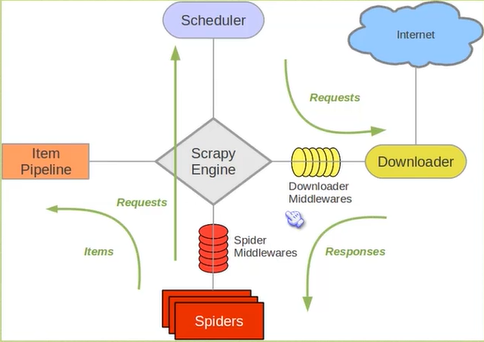
Scrapy:
文件夹:
tutorial/
scrapy.cfg#项目配置文件
tutorial/#模块的代码
__init__.py
items.py#容器
pipelines.py#容器
settings.py#设置文件
spiders/#需要添加的地方
__init__.py
......
1.创建一个Scrapy项目
2.定义Item容器:保存爬取到的数据的容器,其使用方法和python字典类似,并且提供了额外保护机制避免拼写错误导致的未定义字段错误
资源的名字,资源的超链接,资源的描述
在item.py添加:
class Tutorialitem(scrapy.Item)
title = scrapy.Field()#资源名称
link = scrapy.Field()#资源链接
desc = scrapy.Field()#资源描述
函数名可以修改
3.编写爬虫
spider是用户编写用于从网站上爬取数据的类。
其中包含了一个用于下载的初始URL,然后是如何跟网页中的链接以及如何分析页面中的内容,还有提取生成item的方法
spiders文件下
创建一个.py文件
import scrapy
class DmozSpider(scrapy.Spider):
#---------------------Request---------------------
name = "dmoz"#唯一,爬虫的名字
allowed_domains = ['dmoz.org']#爬取的范围
start_urls = ["", "", ......]#开始的网址
#-------------------------------------------------
#---------------------Responses-------------------
def parse(self, response):
filename = response.url.spilt("/")[-2]
withh open(filename, "wb") as f:
f.write(response.body)
#-------------------------------------------------
4.存储内容,机制:Scrapy Selectors选择器
从网页中找到title, link, desc
在tutorial目录下cmd:
scrapy shell "网址"#载入shell,即Scrapy Selectors选择器,得到response的回应
response.body#网页代码
response.headers#网页头
response.xpath("//title")#查找带有标签的结点
response.xpath("//title").extract()#将xpath得到的列表中的结点字符串化
response.xpath("//title/text()").extract()#得到节点的内容,通过字符串显示
sel.xpath('//url/li')#查找url下的li................没有sel变量,可以用responsed代替
sel.xpath('//url/li/text').extract()#获取内容,字符串显示
sel.xpath('//url/li/a/text').extract()#获取内容,字符串显示
sel.xpath('//url/li/a/@href').extract()#获取网址的链接
sites = sel.xpath('//ul[@class='derectory-url']/li')#查找指定的class的节点
for site in sites:
title = site.xpath('a/text()').extract()
exit()#退出
修改爬虫代码:parse
from toturial/items import DmozItem()#导入item类
def parse(self, response):
sel = scrapy.selector.Selector(response)#手动创建选择器对象
sites = sel.xpath('//ul[@class='derectory-url']/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.xpath('a/text()').extract()
item['link ']= site.xpath('a/@href').extract()
item['desc'] = dite.xpath('text()').extract()
items.append(item)
return items
运行爬虫
导出:cmd
scrapy craul dmoz -o items.json -t json
1之前----命令行:cmd
cd Desktop
scrapy startproject 项目名(tutorial文件夹)#创建文件
3之后----写好文件后:cmd
cd tutorial
scrapy crawl dmoz(爬虫的名字)运行爬虫
目录下出现:
books
Resouces#网页的源代码
顺序:
根据爬虫的名字找到爬虫,将Requests传出去
收到Responses时,调用parse
Scrapy Selectors选择器:
基本方法:
xpath()#传入xpath表达式,返回该表达式所对应的所有结点的selector list列表
css()#传入css表达式,返回该表达式所对应的所有结点的selector list列表
extract()#序列化该节点为unicode字符串并返回list
re()#根据传入的正则表达式对数据进行提取,返回unicode字符串list列表
XPath是一门在网页中查找特定信息的语言。所以用XPath筛选数据,比用正则表达式容易些