数据采集最传统的方式是企业自己的生产系统产生的数据,除上述生产系统中的数据外,企业的信息系统还充斥着大量的用户行为数据、日志式的活动数据、事件信息等,越来越多的企业通过架设日志采集系统来保存这些数据,希望通过这些数据获取其商业或社会价值。
Topics
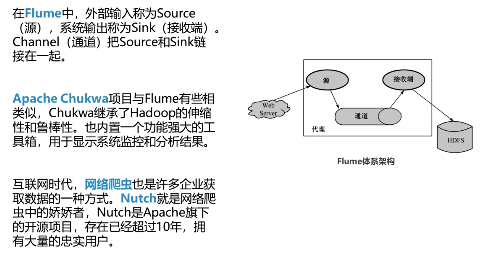
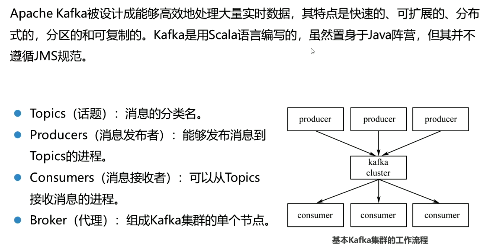
Topics是消息的分类名(或Feed的名称)。Kafka集群或Broker为每一个Topic都会维护一个分区日志。每一个分区日志是有序的消息序列,消息是连续追加到分区日志上,并且这些消息是不可更改的。
日志区分
一个Topic可以有多个分区,这些分区可以作为并行处理的单元,从而使Kafka有能力高效地处理大量数据。
Producers
Producers是向它们选择的主题发布数据。生产者可以选择分配某个主题到哪个分区上。这可以通过使用循环的方式或通过任何其他的语义分函数来实现。
Consumers
Kafka提供一种单独的消费者抽象,此抽象具有两种模式的特征消费组:Queuing和Publish-Subscribe。
Apache Kafka的安装及使用
因为Kafka是处理网络上请求,所以,应该为其创建一个专用的用户,这将便于对Kafka相关服务的管理,减少对服务器上其他服务的影响。
通过数据预处理工作,可以使残缺的数据完整,并将错误的数据纠正、多余的数据去除,进而将所需的数据挑选出来,并且进行数据集成。数据预处理的常见方法有数据清洗、数据集成与数据变换。

噪声是被测量的变量的随机误差或方差。给定一个数值属性,如何才能使数据“光滑”,去掉噪声?下面给出数据光滑技术的具体内容。
分箱
分箱方法通过考察某—数据周国数据的值,即“近邻”来光滑有序数据的值。
回归
光滑数据可以通过一个函数拟合数据来实现。线性回归回归的日标就是查找拟合两个属性的“最佳”线,使得其中一个屈性可以用于预测出另一个属性。
聚类
离群点可通过聚类进行检测,将类似的值组织成群或聚类簇,离群点即为落在簇集合之外的值。许多数据光滑的方法也是涉及离散化的数据归约方法。
数据清洗可以视为一个过程,包括检测偏差与纠正偏差两个步骤:
检查偏差
可以使用已有的关于数据性质的知识发现噪声、_离群点和需要考察的不寻常的值。这种知识或“关于数据的数据”称为元数据。
纠正偏差
即一旦发现偏差。通常需要定义并使用一系列的变换来纠正它们。但这些丁具只支持有限的变换,因此,常常可能需要为数据洁洗过程的这一步编写定制的程序。
数据挖掘经常需要数据集成合并来自多个数据存储的数据。数据还可能需要变换成适于挖掘的形式。数据分析任务多半涉及数据集成。
- 模式集成和对象匹配问题
- 冗余问题
- 元组重复
- 数据值冲突的检测与处理问题
数据变换的目的是将数据变换或统一成适合挖掘的形式。数据变换主要涉及以下内容:
1、光滑。去除数据中的噪声
2、聚集。对数据进行汇总或聚集。
3、数据泛化。使用概念分层,用高层概念替换低层或“原始”数据
4、规范化。将属性数据按比例缩放,使之落入一个小的特定区间
5、属性构造。可以构造新的属性并添加到属性集中,以帮助挖掘过程
数据仓库,是在企业管理和决策中面向主题的、集成的、随时间变化的、非易失性数据的集合。
数据仓库中的数据来自于多种业务数据源,这些数据源可能处于不同硬件平台上,使用不同的操作系统,数据模型也相差很远。如何获取并向数据仓库加载这些数据量大、种类多的数据,已.成为建立数据仓库所面临的一个关键问题。
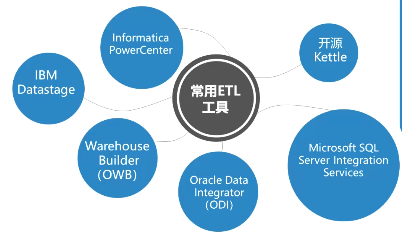
如何获取并向数据仓库加载数据量大、种类多的数据,一般要使用专业的数规抽取、转换和装截工具,这些工具常用ETL合开起来被称为工具ETL (Extract-Transform-Load) 。
PowerCenter
lnformatica的PowerCenter是一个可扩展、高性能企业数据集成平台,应用于各种数据集成流程,通过该平台可实现自动化、重复使用及灵活性。
IBM Datastage
IBM IlnfoSphere DataStage是一款功能强大的ETL工具。是IBM数据集成平台IBMlnformation Server的一部分,是专门的数据提取、数据转换、数据发布的工具。
Kettle
Kettle是Pentaho中的ETL工具,Pentaho是一套开源Bl解决方案。Kettle是一款国外优秀的开源ETL工具,由纯Java编写,可以在Windows、Linux、UNIX上运行,无须安装,数据抽取高效稳定。