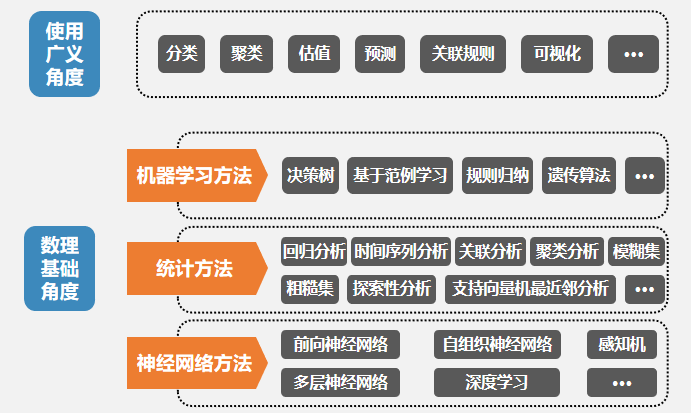
从科学定义分析,数据挖掘是从大量的、有噪声的、不完全的、模糊和随机的数据中,提取出隐含在其中的、人们事先不知道的、具有潜在利用价值的信息和知识的过程。
从技术角度分析,数据挖掘就是利用一系列的相关算法和技术,从大数据中提取出行业或公司所需要的、有实际应用价值的知识的过程。知识表示形式可以是概念、规律、规则与模式等。
准确地说,数据挖掘是整个知识发现流程中的一个具体步骤,也是知识发现过程中最重要的核心步骤。
- 处理大数据的能力更强,且无须太专业的统计背景就可以使用数据挖掘工具
- 从使用与需求的角度上看,数据挖掘工具更符合企业界的需求
- 数据挖掘的最终目的是方便企业终端用户使用,而并非给统计学家检测用的
分类
数据挖掘方法中的一种重要方法就是分类,在给定数据基础上构建分类函数或分类模型,该函数或模型能够把数据归类为给定类别中的某一种类别,这就是分类的概念。
聚类
聚类也就是将抽象对象的集合分为相似对象组成的多个类的过程,聚类过程生成的簇称为一组数据对象的集合。
关联规则
关联规则属于数据挖掘算法中的一类重要方法,关联规则就是支持度与信任度分别满足用户给定阈值的规则。
时间序列预测
时间序列预测法是一种历史引申预测法,也即将时间数列所反映的事件发展过程进行引申外推,预测发展趋势的一种方法。
根据适用的范围,数据挖掘工具分为两类:专用挖掘工具和通用挖掘工具。专用数据挖掘工具针对某个特定领域的问题提供解决方案,在涉及算法的时候充分考虑数据、需求的特殊性。对任何应用领域,专业的统计研发人员都可以开发特定的数据挖掘工具。
Weka软件
公开的数据挖掘工作平台,集成大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理、分类、回归、聚类、关联规则,以及交互式界面上的可视化。
SPSS软件
SPSS采用类似Excel表格的方式输入与管理数据,数据接口较为通用,能方便地从其他数据库中读入数据。突出的特点是操作界面友好,且输出结果美观。
Clementine软件
Clementine提供出色、广泛的数据挖掘技术,确保用恰当的分析技术来处理相应的商业问题,得到最优的结果以应对随时出现的问题。
RapidMiner软件
RapidMiner并不支持分析流程图方式,当包含的运算符比较多时就不容易查看;具有丰富的数据挖掘分析和算法功能,常用于解决各种商业关键问题。
其他数据挖掘软件
Orange、Knime、Keel与Tanagra等
分类是一种重要的数据分析形式,根据重要数据类的特征向量值及其他约束条件,构造分类函数或分类模型(分类器),目的是根据数据集的特点把未知类别的样本映射到给定类别中。数据分类过程主要包括两个步骤,即学习和分类。
分类分析在数据挖掘中是一项比较重要的任务,目前在商业上应用最多。
分类的目的是从历史数据记录中自动推导出对给定数据的推广描述,从而学会一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个类中。
为建立模型而被分析的数据元组形成训练数据集,由一组数据库记录或元组构成,每个元组是一个由有关字段(又称属性或特征)值组成的特征向量,此外,每一个训练样本都有一个预先定义的类别标记,由一个被称为类标签的属性确定。
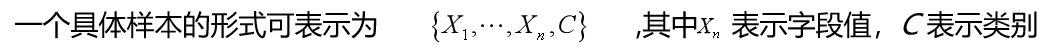
分类又称为有监督的学习
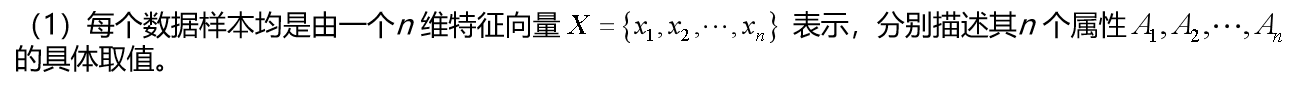


支持向量机(Support Vector Machine)是建立在统计学习理论的VC 维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(对特定训练样本的学习精度,Accuracy)和学习能力(无错误地识别任意样本的能力)之间寻求最佳折中,以期获得最好的推广能力(或称泛化能力)。
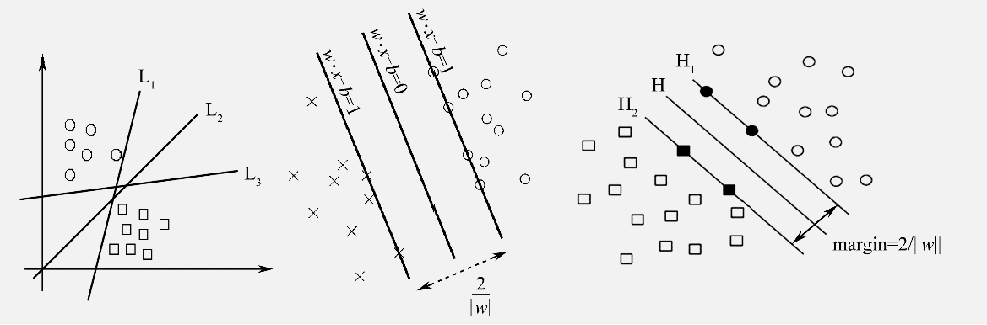
SVM最基本的任务就是找到一个能够让两类数据都离超平面很远的超平面,在分开数据的超平面的两边建有两个互相平行的超平面。分隔超平面使两个平行超平面的距离最大化,平行超平面间的距离或差距越大,分类器的总误差越小。
通常希望分类的过程是一个机器学习的过程。设样本属于两个类,用该样本训练SVM得到的最大间隔超平面。在超平面上的样本点也称为支持向量。
- 线性可分情形SVM
- 非线性可分情形SVM
- 支持向量机(SVM)的核函数
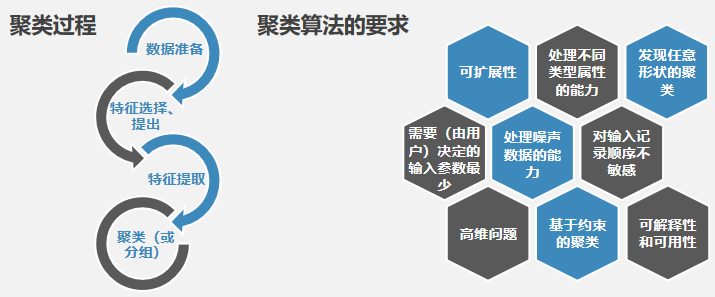
聚类(clustering)就是将具体或抽象对象的集合分组成由相似对象组成的为多个类或簇的过程。由聚类生成的簇是一组数据对象的集合,簇必须同时满足以下两个条件:每个簇至少包含一个数据对象;每个数据对象必须属于且唯一地属于一个簇。
聚类分析是指用数学的方法来研究与处理给定对象的分类,主要是从数据集中寻找数据间的相似性,并以此对数据进行分类,使得同一个簇中的数据对象尽可能相似,不同簇中的数据对象尽可能相异,从而发现数据中隐含的、有用的信息。
层次聚类算法
层次聚类算法的指导思想是对给定待聚类数据集合进行层次化分解。此算法又称为数据类算法,此算法根据一定的链接规则将数据以层次架构分裂或聚合,最终形成聚类结果。
从算法的选择上看,层次聚类分为自顶而下的分裂聚类和自下而上的聚合聚类。
分裂聚类初始将所有待聚类项看成同一类,然后找出其中与该类中其他项最不相似的类分裂出去形成两类。如此反复执行,直到所有项自成一类。
聚合聚类初始将所有待聚类项都视为独立的一类,通过连接规则,包括单连接、全连接、类间平均连接,以及采用欧氏距离作为相似度计算的算法,将相似度最高的两个类合并成一个类。如此反复执行,直到所有项并入同一个类。
典型代表算法,BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies,利用层次方法的平衡迭代规约和聚类)
划分聚类算法
划分法属于硬聚类,指导思想是将给定的数据集初始分裂为K个簇,每个簇至少包含一条数据记录,然后通过反复迭代至每个簇不再改变即得出聚类结果。
K-Means算法也称作K-平均值算法或者K均值算法,是一种得到广泛使用的聚类分析算法。

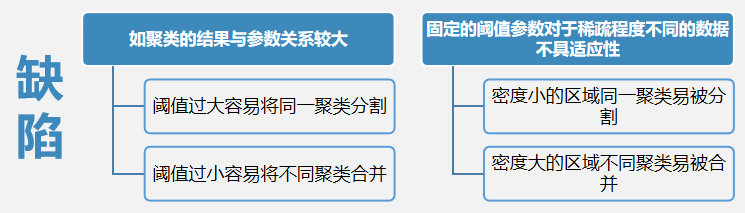
基于密度的聚类算法
基于密度聚类的经典算法DBSCAN(Density-Based Spatial Clustering of Application with Noise,具有噪声的基于密度的空间聚类应用)是一种基于高密度连接区域的密度聚类算法。
DBSCAN的基本算法流程如下:从任意对象P 开始根据阈值和参数通过广度优先搜索提取从P 密度可达的所有对象,得到一个聚类。若P 是核心对象,则可以一次标记相应对象为当前类并以此为基础进行扩展。得到一个完整的聚类后,再选择一个新的对象重复上述过程。若P 是边界对象,则将其标记为噪声并舍弃
基于网格的聚类算法
基于网格的聚类算法是采用一个多分辨率的网格数据结构,即将空间量化为有限数目的单元,这些单元形成了网格结构,所有的聚类操作都在网格上进行。
- STING(STatistical INformation Grid,统计信息网格)算法将空间区域划分为矩形单元。针对不同级别的分辨率,通常存在多个级别的矩形单元,这些单元形成了一个层次结构——高层的每个单元被划分为多个低一层的单元。
- WaveCluster(Clustering using wavelet transformation,采用小波变换聚类)是一种多分辨率的聚类算法。先通过在数据空间上加一个多维网格结构来汇总数据,然后采用一种小波变换来变换原特征空间,在变换后的空间中找到密集区域。
基于模型的聚类算法
基于模型的聚类算法是为每一个聚类假定了一个模型,寻找数据对给定模型的最佳拟合。
- 统计学方法(EM和COBWEB算法)。概念聚类是机器学习中的一种聚类方法,给出一组未标记的数据对象,它产生一个分类模式。概念聚类除了确定相似对象的分组外,还为每组对象发现了特征描述,即每组对象代表了一个概念或类。概念聚类过程主要有两个步骤:首先,完成聚类;其次,进行特征描述。
- 神经网络方法(SOM算法)。神经网络方法将每个簇描述成一个模型。模型作为聚类的一个“原型”,不一定对应一个特定的数据实例或对象。神经网络聚类的两种方法:竞争学习方法与自组织特征图映射方法。神经网络聚类方法存在较长处理时间和复杂数据中复杂关系问题,还不适合处理大数据库。
关联规则是数据挖掘中最活跃的研究方法之一,是指搜索业务系统中的所有细节或事务,找出所有能把一组事件或数据项与另一组事件或数据项联系起来的规则,以获得存在于数据库中的不为人知的或不能确定的信息,它侧重于确定数据中不同领域之间的联系,也是在无指导学习系统中挖掘本地模式的最普通形式。
一般来说,关联规则挖掘是指从一个大型的数据集(Dataset)发现有趣的关联(Association)或相关关系(Correlation),即从数据集中识别出频繁出现的属性值集(Sets of Attribute Values),也称为频繁项集(Frequent Itemsets,频繁集),然后利用这些频繁项集创建描述关联关系的规则的过程。
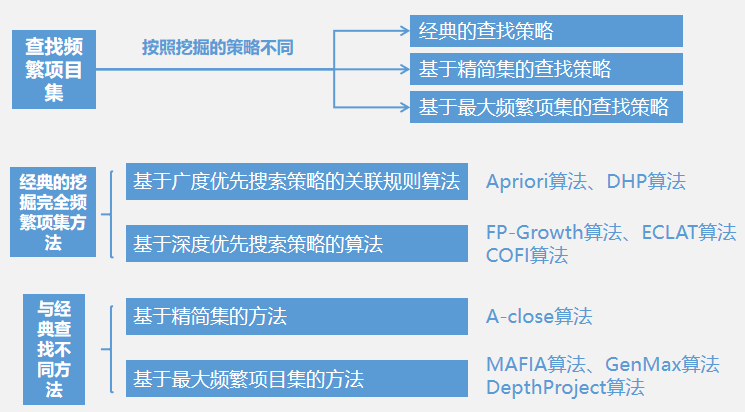
发现频繁项集
发现所有的频繁项集是形成关联规则的基础。通过用户给定的最小支持度,寻找所有支持度大于或等于Minsupport的频繁项集。
生成关联规则
通过用户给定的最小可信度,在每个最大频繁项集中,寻找可信度不小于Minconfidence的关联规则。
如何迅速高效地发现所有频繁项集,是关联规则挖掘的核心问题,也是衡量关联规则挖掘算法效率的重要标准。
格结构(Lattice Structure)常常被用来枚举所有可能的项集。
Apriori算法
Apriori算法基于频繁项集性质的先验知识,使用由下至上逐层搜索的迭代方法,即从频繁1项集开始,采用频繁k项集搜索频繁k+1项集,直到不能找到包含更多项的频繁项集为止。

FP-Growth算法
频繁模式树增长算法(Frequent Pattern Tree Growth)采用分而治之的基本思想,将数据库中的频繁项集压缩到一棵频繁模式树中,同时保持项集之间的关联关系。然后将这棵压缩后的频繁模式树分成一些条件子树,每个条件子树对应一个频繁项,从而获得频繁项集,最后进行关联规则挖掘。
- 扫描事务数据库D,生成频繁1项集L1
- 将频繁1项集L1按照支持度递减顺序排序,得到排序后的项集L1
- 构造FP树
- 通过后缀模式与条件FP树产生的频繁模式连接实现模式增长
辛普森悖论
虽然关联规则挖掘可以发现项目之间的有趣关系,在某些情况下,隐藏的变量可能会导致观察到的一对变量之间的联系消失或逆转方向,这种现象就是所谓的辛普森悖论(Simpson's Paradox)。
为了避免辛普森悖论的出现,就需要斟酌各个分组的权重,并以一定的系数去消除以分组数据基数差异所造成的影响。同时必须了解清楚情况,是否存在潜在因素,综合考虑。
分类技术或分类法(Classification)是一种根据输入样本集建立类别模型,并按照类别模型对未知样本类标号进行标记的方法。

决策树
决策树就是通过一系列规则对数据进行分类的过程。
决策树分类算法通常分为两个步骤:构造决策树和修剪决策树。

k-最近邻

最近邻分类是基于要求的或懒散的学习法,即它存放所有的训练样本,并且直到新的(未标记的)样本需要分类时才建立分类。其优点是可以生成任意形状的决策边界,能提供更加灵活的模型表示。
预测分析是一种统计或数据挖掘解决方案,包含可在结构化与非结构化数据中使用以确定未来结果的算法和技术,可为预测、优化、预报和模拟等许多其他相关用途而使用。
时间序列预测是一种历史资料延伸预测,以时间序列所能反映的社会经济现象的发展过程和规律性,进行引申外推预测发展趋势的方法。
时间序列预测及数据挖掘分类:
- 依据研究的方式分类
- 将时间序列数据作为一种特殊的挖掘对象,找寻对应的数据挖掘算法进行专门研究
- 从时间序列数据中提取并组建特征,仍用原有的数据挖掘框架与算法进行数据挖掘
- 依据研究的内容分类
- 时态模式挖掘
- 相似性问题挖掘
- 依据研究的对象分类
- 事件序列的数据挖掘
- 事务序列的数据挖掘
- 数值序列的数据挖掘
- 依据预测方法的性质
- 定性预测方法
- 时间序列预测
- 因果关系预测

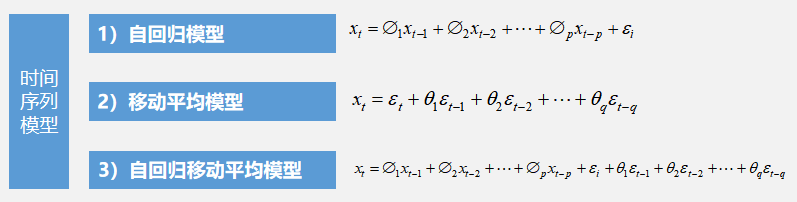
时间序列:对按时间顺序排列而成的观测值集合,进行数据的预测或预估。
典型的算法:序贯模式挖掘SPMGC算法
序贯模式挖掘算法SPMGC(Sequential Pattern Mining Based on General Constrains)SPMGC算法可以有效地发现有价值的数据序列模式,提供给大数据专家们进行各类时间序列的相似性与预测研究。
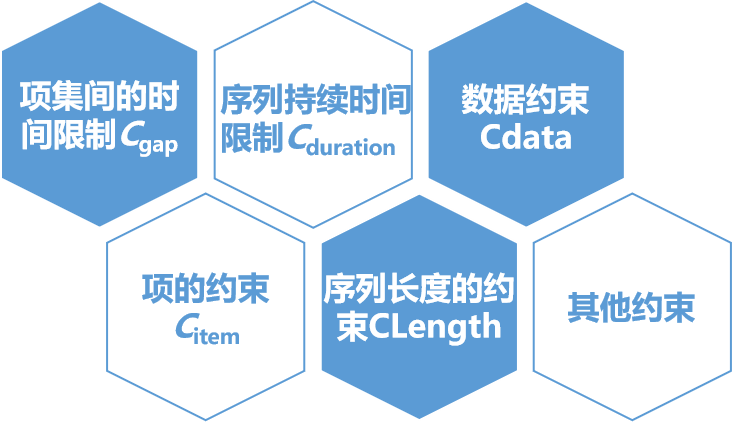
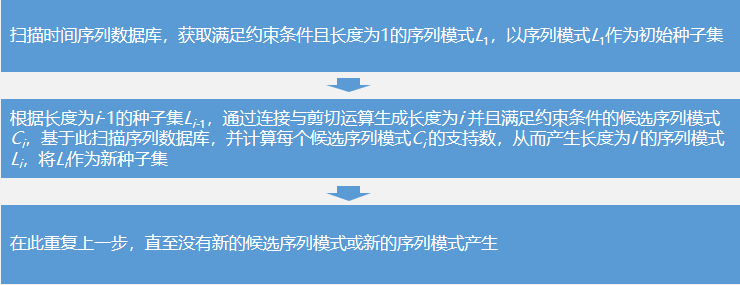
SPBGC算法首先对约束条件按照优先级进行排序,然后依据约束条件产生候选序列。SPBGC算法说明了怎样使用约束条件来挖掘序贯模式,然而,由于应用领域的不同,具体的约束条件也不尽相同,同时产生频繁序列的过程也可采用其他序贯模式算法。